
안녕하세요 ! 브라이틱스 서포터즈 김유민입니다.
이번 시간에는 저번 시간에 이어 !
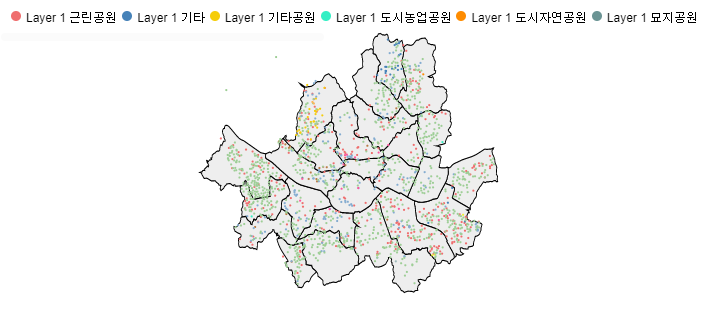
서울 시에 위치하고 있는 여러 운동 시설들의 위치를 한 눈에 볼 수 있게
지도에 시각화해보려고 해요
지난 시간에는 단순히 군집별로 같은 색을 사용해서
각 시군구마다 어떤 군집인지를 확인할 수 있었다면,
이번에는 여러 시설들이 시군구 곳곳에 어떻게 자리잡고 있는지를
좀 더 업그레이드 버전 ! 으루 만나보실 수 있을 겁니다.
⏩⏩⏩
(여러분들의 흥미를 돋우기 위해서 완성본 투척)

지도 시각화를 위한 기본적인 준비과정은 아래 포스팅을 참고해주세요 :)
[Brightics | 프로젝트] 서울시 지도 시각화하기 : 브라이틱스 Map vs 파이썬 Forlium 비교
이번 시간은 지난 포스팅에서 예고한 대로 브라이틱스를 활용한 지도 시각화 방법을 공유해드릴까 합니다 !! 아무래도 도시 연구나 지역 간 비교를 할 때 직접 지도 위에서 수치를 나타내
uumini.tistory.com
제가 공원과 자전거 대여소 위치를 알아보려고 하는 이유는
일단, 건강도시를 위한 인프라 전반을 체크해보기 위함이에요 !
공원, 수변 지역, 체육 및 운동시설, 자전거 도로 등 시민운동을 위한 인프라가
각 지역마다 잘 배치되어 있는지 ..!
제가 사용할 데이터는
전국도시공원정보표준데이터 / 서울특별시 공공자전거 대여소 정보 입니다.
전국도시공원정보표준데이터
도시공원정보(공원유형, 보유시설 등)를 제공합니다. 공공데이터 개방 표준데이터 속성정보(표현형식/단위 등)는 [공공데이터 개방 표준]고시를 참고하시기 바랍니다.(정보공유>자료실>법령(고
www.data.go.kr
https://data.seoul.go.kr/dataList/OA-13252/F/1/datasetView.do
도시공원
여느때나 다름없이 순조롭게 데이터를 다운받으려는 순간

⛔ 에러 발생 ⛔
다운 받는 과정에서부터 난관에 봉착했는데요 ㅠ!!

이 정도는 저번 시간에도 겪은 문제이니
당황하지 않고 ...
csv 파일을 UTF 8(쉼표로 분리) 로 택해서 저장해줍니다
그 후 다시 로드를 해주려고 보니

⛔ 에러 발생 2 ⛔
빨리 Detail 부분을 확인해봤어요
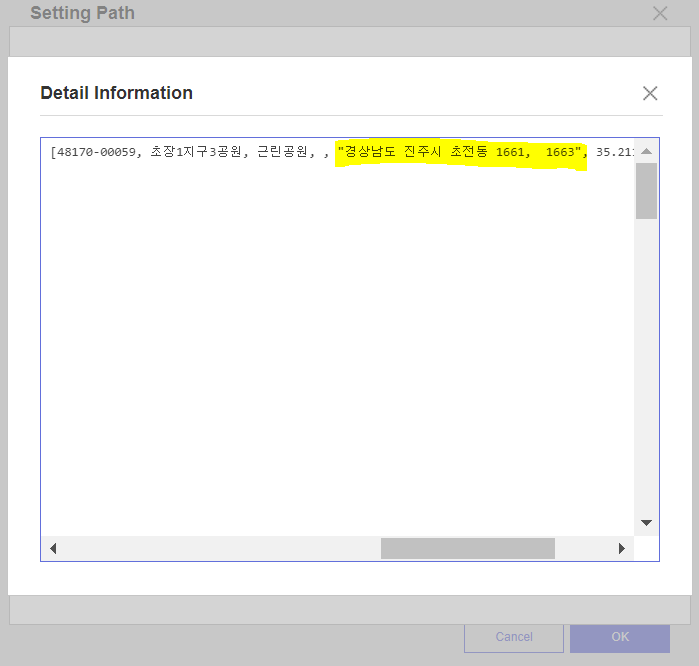
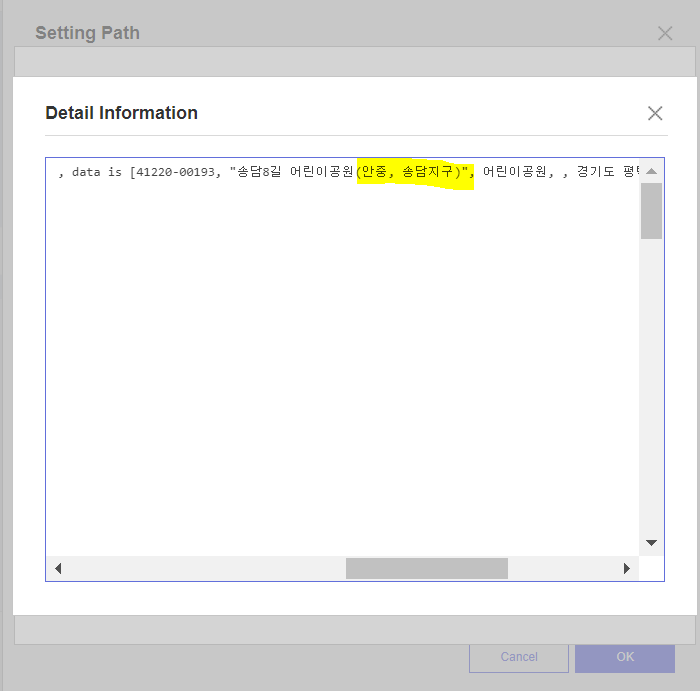
그랬더니 데이터 칼럼 각각 안에서 쉼표가 존재하고 있더라구요.
쉼표로 각 변수를 구분하고 있었는데 쉼표가 중복으로 인식된 모양이더라구요 !!
공원 이름, 소재지 도로명 주소, 소재지지번주소 까지 처리해주어야 했습니다.
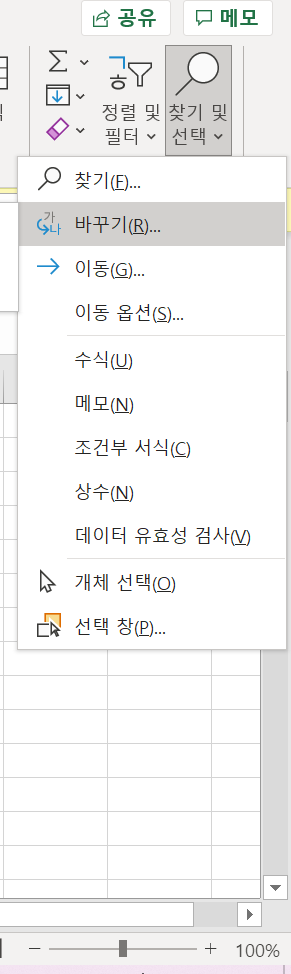
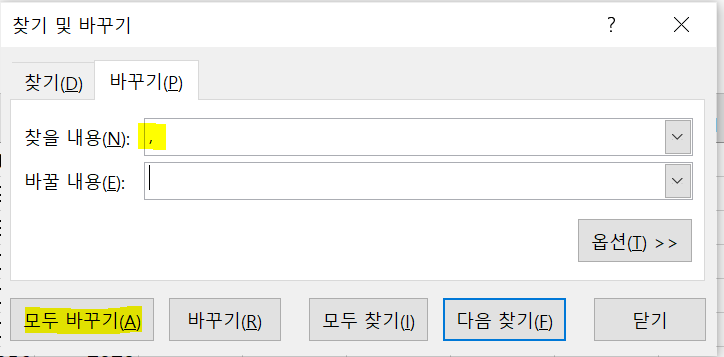
제가 추천드리는 방법은 바로,
찾기 및 선택 -> 바꾸기 -> 찾을 내용 : 쉼표(,) -> 바꿀 내용 : 공백() -> 모두 바꾸기
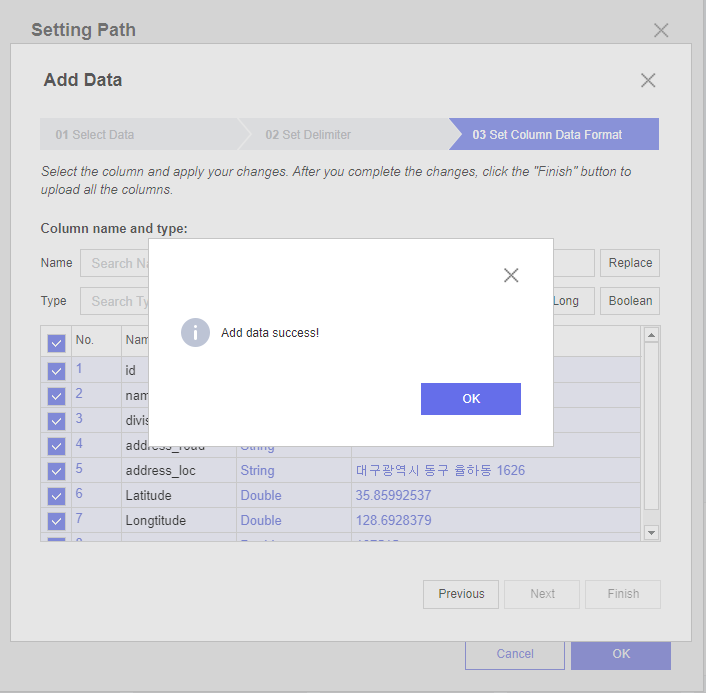
드디어 로드가 완료되었습니다 !!
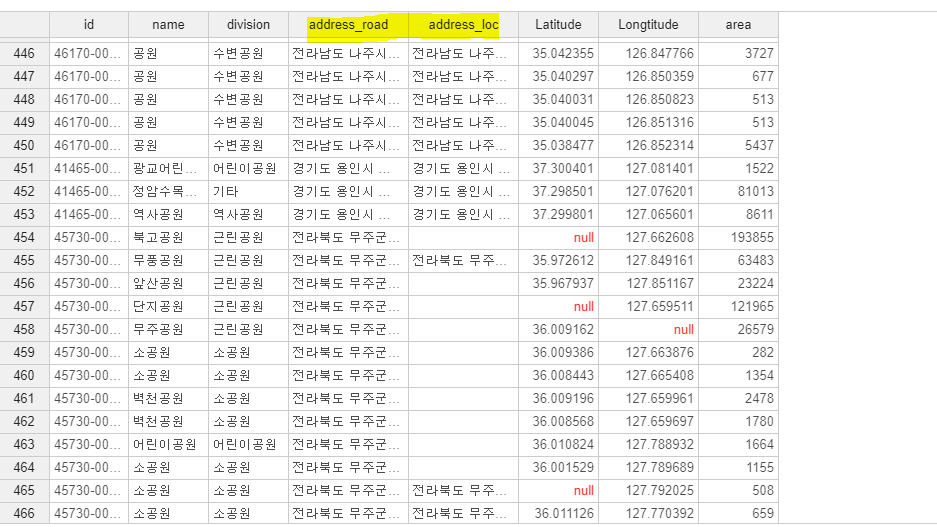

이제 데이터를 찬찬히 훑어보니 전국구 단위이다보니
소재지 도로명 주소와 소재지 지번 주소를 참고해서 서울자료만을 추출하려고 했어요.
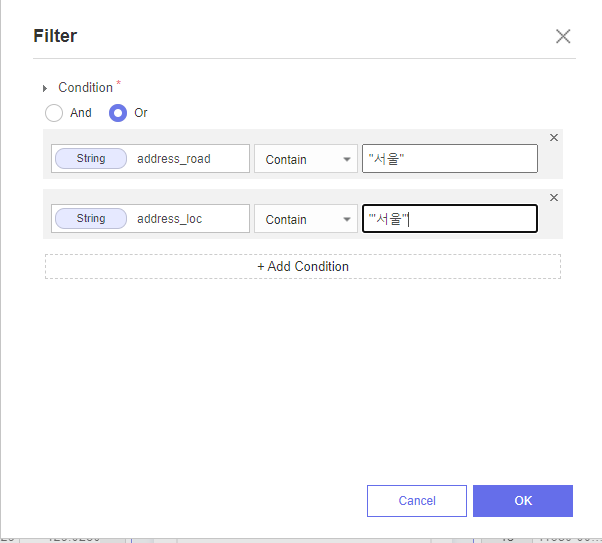

⛔ 에러 발생 3 ⛔
오늘은 에러의 날인가봐요 ^^ ..
뭐가 틀렸는지 보이시나요 ...?
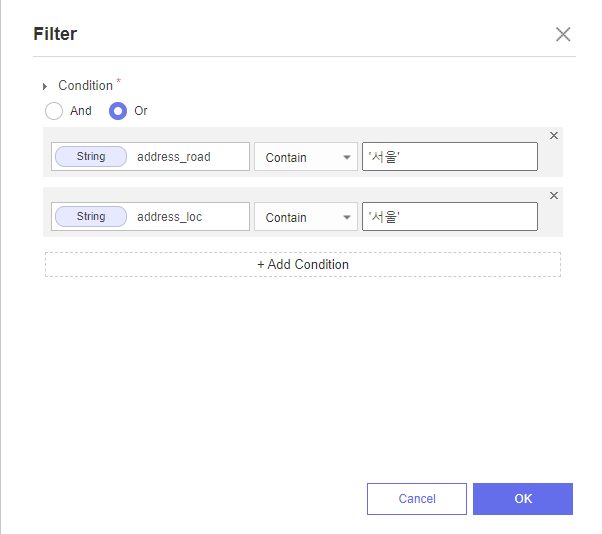
정말 .. 별게 아니라서 정말 별게 되어버렸던 ..
바로 FILTER를 할 때 문자열에 "큰 따옴표 " 가 아닌 '작은 따옴표' 가 들어가야했어요 !
그렇게 완성된 데이터로 서울시 json파일을 활용해서
아래와 같이 지도를 완성해보았습니다
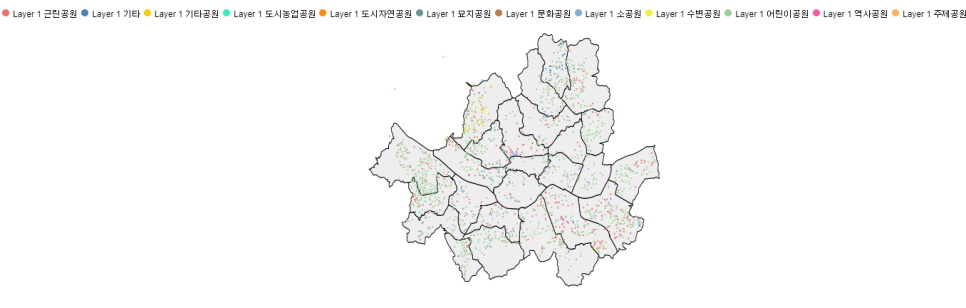
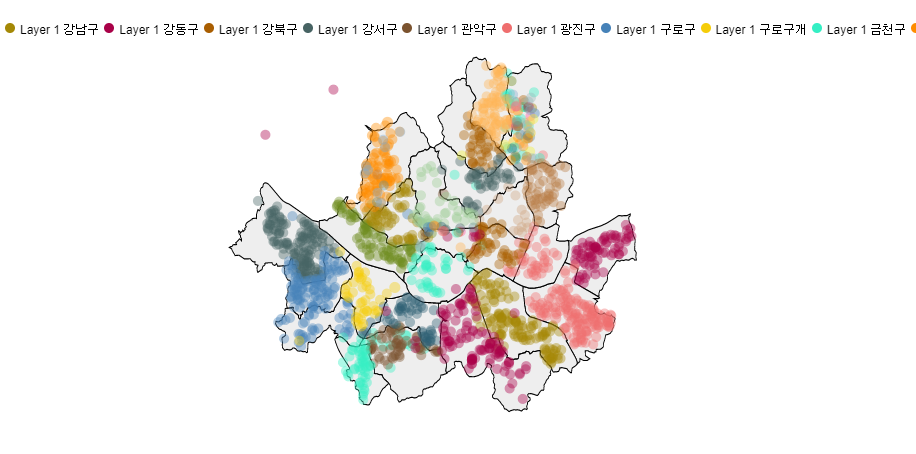
최종적으로 마지막 지도를 보시면 , 확실히 군집3에 속한 강북구, 성북구, 중랑구의 밀집도가 군집1보다 매우 낮습니다.
서울시 공공자전거 대여소 위치 정보
이번엔 서울시 공공자전거 대여소 데이터를 가져와봤어요.
공공자전거 대여소와 같이 자전거도로 현황도 함께 보면 좋지 않을까하는 생각도 드네요.
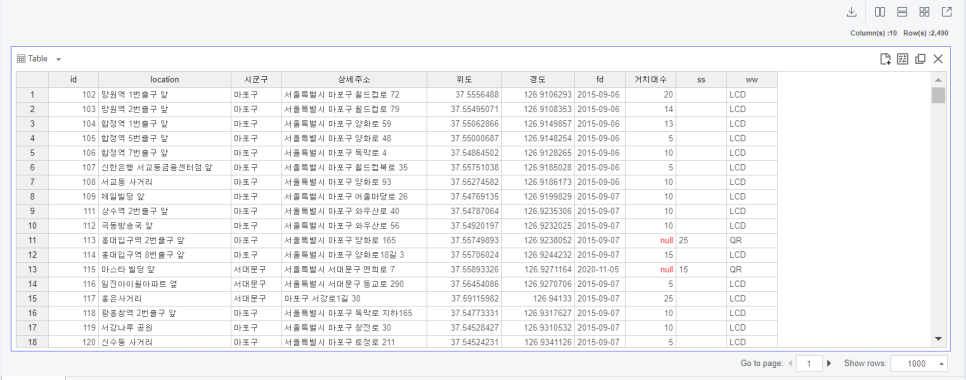
뚝딱 뚝딱
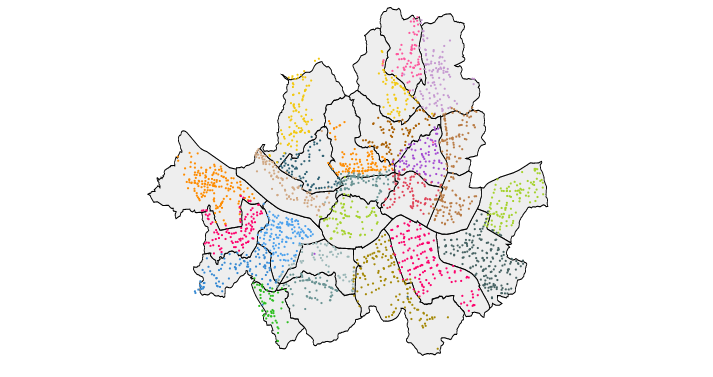
시군구별 자전거대여소 위치는 이렇게 나오네요 !!!
매우 칼라풀하고 이뻐보입니다 ㅎㅎㅎ
그치만 크기를 비교하긴 힘들 것 같아서 Tree MAP을 사용해보았습니다.

확실히 시군구별 차이가 존재해보이죠 ~?
텍스트 분석 :: 자전거 대여소는 어디서 발견할 수 있을까 ??
이때 추가적으로 !!!
자전거 대여소는 주로 어디쯤에서 볼 수 있는지를 확인해보고 싶었어요.
그래서 브라이틱스 내에서 텍스트분석을 진행해보았어요.
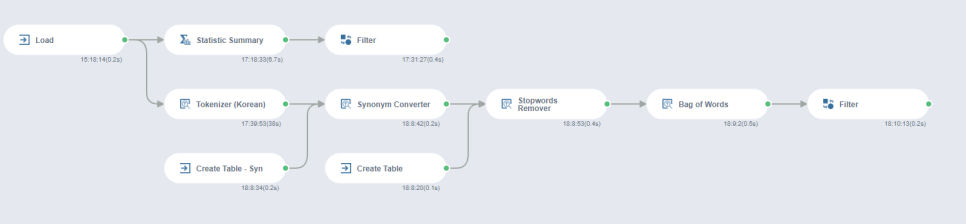

가장 먼저 해주어야하는 작업은
Tokenizer 함수인데요, 이는 텍스트를 원하는 품사(명사, 형용사, 동사, 부사, 등)으로 쪼개는 과정이에요.
텍스트 분석은 주로 영화리뷰, 감정분석, 자주 사용되는 단어 찾기 등
긴 문장 형태의 데이터에서 어떠한 아이디어를 얻기 위해 사용되는데요,
저는 위치 location 변수를 '명사'별로 나누어 보았습니다.

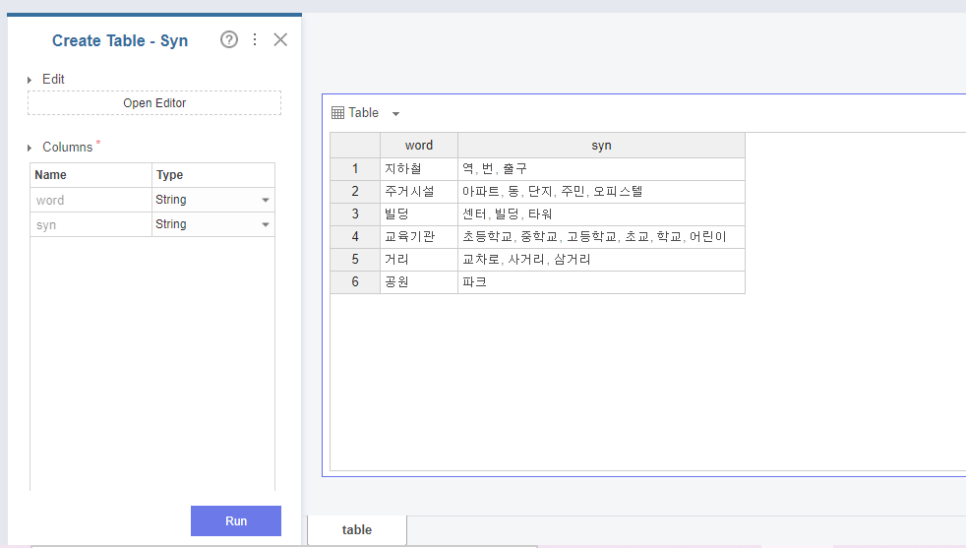
다음으로는 Synonym Converter 함수에요.
토큰화 한 단어들에서 중 유사한 의미를 가진 단어들을 하나의 공통된 단어로 지정해주는 거에요.
이때 Create Table로 직접 유의어들의 Synonym Dictionary 를 만들어주면 됩니다
예를 들면 역, 번, 출구 => 지하철 아파트, 동, 단지, 오피스텔 => 주거시설 이렇게요


그리고 Stopwords Remover 함수는
텍스트 분석 시에 불필요한 단어들을 직접 Dictionary 형태로 지정해주어 제거하는 과정이랍니다.
+ 물론 따로 dictionary 를 적지 않고 바로 함수 내에서 리스트를 작성할 수도 있답니다.
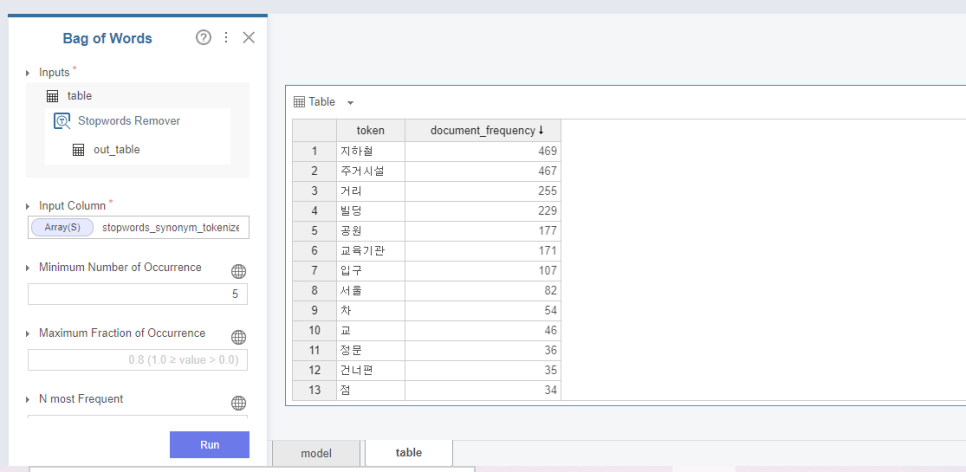
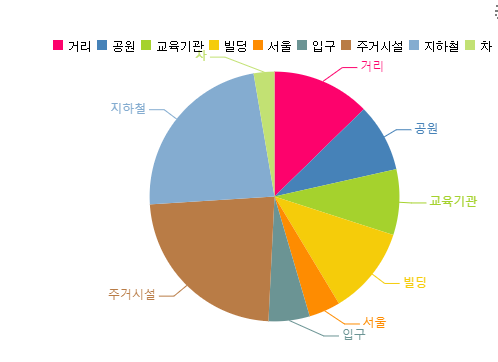
이제 마지막으로 !!!
Bag of Words 함수를 통해
토큰화된 단어들 중 가장 빈번히 나타나는 단어의 빈도 수를 확인해줍시다.
확인해본 결과 지하철 역 근처, 그리고 주거시설 가까이에 공공자전거가 주로 설치되어있네요 ㅎㅎㅎ
https://www.brightics.ai/kr/docs/ai/s1.0/tutorials/260_py_nonsmoking_area_analysis?type=insight
Brightics Studio
www.brightics.ai
참고로 제가 참고한 튜토리얼은 이겁니다 !
이상으로
<서울 시민들의 운동인프라를 위한 시설들이 어떻게 분포되어 있을까 ! >
에 대해 알아보는 시간이었습니다 :)
*해당 게시글은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.
게시글 관련 문의 및 소통을 원하신다면 아래 댓글로 남겨주세요
브라이틱스 사용 중 문의사항은
brightics@samsung.com으로 연락주세요 :)
'대외활동 > Brightics 서포터즈' 카테고리의 다른 글
| [Brightics | Basic] 내 마음대로 데이터 정제(결합, 결측치, 이상치) :: 전처리 모음 (0) | 2021.10.18 |
|---|---|
| [Brightics | 프로젝트] 소득수준이 높을수록 건강수준도 높을까? :: 상관성 분석 (0) | 2021.10.18 |
| [삼성 SDS] ProDS 자격증 합격 후기 / 공부방법 / 독학 후기 / 무료 인강 추천 (0) | 2021.10.05 |
| [Brightics | 프로젝트] 서울시 지도 시각화하기 : 브라이틱스 Map vs 파이썬 Forlium 비교 (0) | 2021.10.05 |
| [Brightics | 프로젝트] 서울시 건강 고위험 지역 군집화 (2) 계층적 군집화(Hierarchical Clustering) (0) | 2021.09.27 |