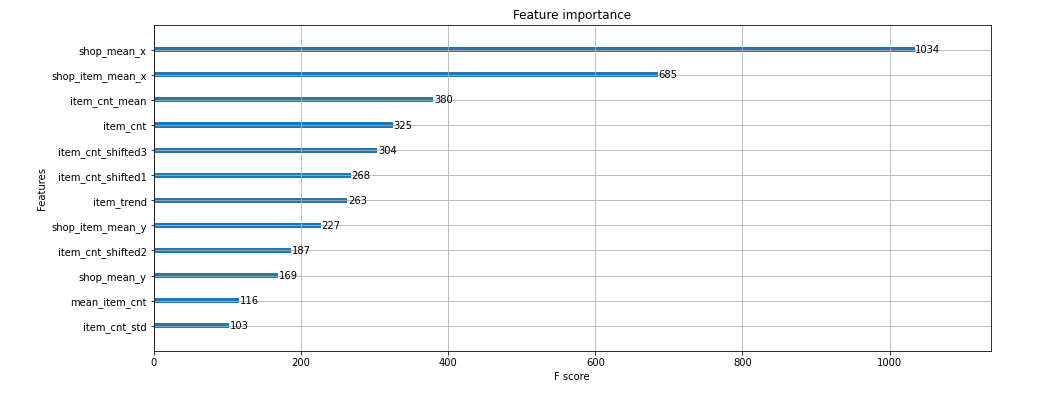
Regression : time-series regression 시계열 작성자 : 14기 김유민 Kaggle : Predict Future Sales 커널 필사 대회 소개 링크 : https://www.kaggle.com/c/competitive-data-science-predict-future-sales 비즈니스 소프트웨어 기업 1c company의 일별 판매 내역 데이터가 제공됨 다음 달 해당 스토어에서 판매되는 제품량 예측 상점 및 제품 목록은 매월 약간씩 변경되며 이러한 상황을 처리할 수 있는 강력한 모델을 만들자. 데이터 파일 sales_train.csv - 2013년 1월부터 2015년 10월까지의 일일 과거 데이터. train set test.csv - 상점과 제품의 2015년 11월 판매량..