학습은 훈련데이터로부터 우리의 매개변수의 최적값을 자동으로 획득하는 단계이다.
여기서 매개변수는 2개, 기울기와 편향이다.
이때 최적값은 실제값과 예측값이 가장 비슷한 지점에서 만들어지겠다.
다시 말하면 loss function을 최소화하는 방향으로 학습을 해야한다는 의미이다.
손실함수의 종류
그래서 loss function의 종류로는 먼저 MSE가 있다.

신경망이 추정한 출력값에서 실제 값과의 차이가 얼마나 되는지를 알려주는 함수고 연속형 변수 예측에 사용된다.
직접 함수로 정의하면 다음과 같이 작성할 수 있다.

보시는 것 처럼 compile() 메소드를 사용해서 학습 방식에 대한 환경설정을 이렇게 해주면 된다.
Compile은 세 개의 인자를 입력으로 받는데
1) optimizer,
2) loss function : 회귀일때는 mse, 분류일 때는 categorical_crossentropy, binary_crossentropy 등을 써줌.
3) metric : 평가 지표를 써주시면 되는 데 주로 분류에서는 accuracy, 회귀에서는 mse, rmse, r^2, mae, mape, 등을 써줌
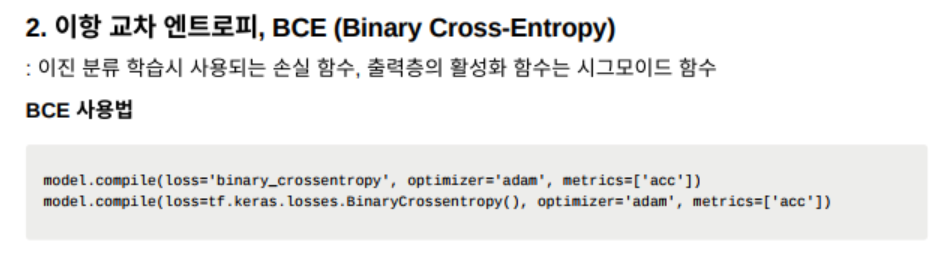
다른 loss function으로 아까 말했던 Binary Cross-Entropy는 출력층의 활성화 함수가 시그모이드 함수인 함수이고,
Categorical Cross-Entropy는 출력층의 활성화 함수가 소프트맥스 함수인 함수이다.

그리고 범주형이지만 One-hot encoding을 생략하고, 정수값을 그대로 레이블로 사용하는 경우에는 sparse_categorical_crossentropy를 사용해준다.
'데이터 스터디 > DL' 카테고리의 다른 글
| 06. 옵티마이저 (optimizer) (0) | 2022.07.16 |
|---|---|
| 05. 경사 하강법 (0) | 2022.07.16 |
| 03. 신경망 추론 - 활성화 함수, 출력층 함수 (0) | 2022.07.16 |
| 02. 인공신경망 (0) | 2022.07.16 |
| 01. 퍼셉트론 (0) | 2022.07.16 |