TF-IDF는 앞서 다루었던 DTM 행렬에서 행렬 내의 각 단어에 대한 중요도를 가중치로 삼아주는 기법이다.
따라서 TF-IDF는 주로 문서의 유사도를 구해서 추천시스템을 만들거나, 검색 결과 중요도를 보여줘서 검색 시스템을 만들거나, 특정 문서에서 키워드의 중요도 키워드 추출을 하는데 쓰이거나 등 되게 많이 사용되고 있다.
TF-IDF

자세히 살펴보자면요, TF-IDF는 말그대로 TF랑 IDF랑 곱한 값을 의미한다.
먼저 TF를 보시면, TF란 terim frequency이다.
이는 특정 문서 d개에서 특정 단어 w의 등장 횟수, 즉 각 문서에서 단어의 등장 빈도를 말한다.
그리고 IDF는 DF, document frequency의 역수에 로그를 취한 형태인데,
DF는 특정 단어W가 문서 안에서 몇 번 등장했는지는 중요하지 않고, 문서 몇 개에서 등장을 했는지를 세어주는 것을 말한다.
이때 분모가 0이 되는 것을 방지하기 위해서 1을 앞에 더해준다. 또한 전체 문서의 개수에서 단어가 포함된 문서의 개수를 나눠준걸로 가중치를 취하고 있는 모습인데, 여기서 LOG를 씌워준 이유는 문서 개수가 많아질수록 즉 분자 n이 커질수록 IDF값이 너무 빠른 속도로 커지기 때문에 조절해주기 위해서 log를 씌워준것이다.
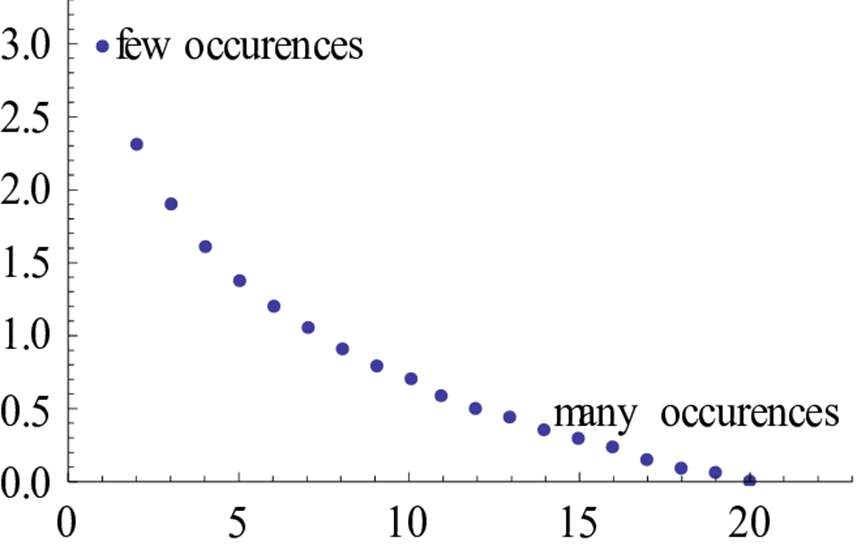
따라서 위 그래프처럼 빈도수가 많이 발생할수록 IDF값이 낮아지는 걸 확인할 수 있고 이걸 가중치로 써주고 있는 모습이다.
=> 단순하게 단어 출현 빈도만 카운트하는 CountVectorizer와 같은 방법을 쓸 순 있지만 조사, 관사 같은 단어들의 중요도를 떨어뜰이기 위해선 많이 등장하는 단어에 패널티를 주고 단어 빈도의 스케일을 맞춰주는 TF-IDF방법을 써주는게 좋다.
'데이터 스터디 > DL' 카테고리의 다른 글
| 07. Back Propagation - 역전파 이해하기 (0) | 2023.11.10 |
|---|---|
| [코드 분석] Bag of Words for IMDB movie review (1) | 2023.02.01 |
| N-gram 언어 모델 (0) | 2022.07.16 |
| 언어 모델 - 통계 기반 언어모델 (0) | 2022.07.16 |
| 자연어 처리 - 통계 기반 기법 (0) | 2022.07.16 |