
Brightics Studio 설치까지 모두 끝냈으니,
이제 본격적으로 Brightics Studio와 친해져볼 시간입니다.
앞으로 쉬운 연습 단계부터 어려운 실습 단계까지 차근차근 따라오실 수 있도록
Basic Level / Intermediate Level / Advanced Level 로 나누어 설명드릴 예정입니다.
독자분들의 수준에 맞게 level을 선택해서 읽어주시면 감사하겠습니다 :)
데이터 분석, 어디서부터 시작할까?
데이터 분석 순서 알고가자
<데이터 분석 프로세스 알아보기>

데이터분석을 하는 과정은
[수집] : 분석 목적에 맞는 데이터를 수집 ex. 공공데이터 포털에서 데이터를 가져오기, 웹크롤링 등
-> [탐색 & 전처리] : 요약 통계량 확인, 결측값 , 이상값 처리
-> [모델링] : 전처리한 데이터를 분할하여 모델 학습하기
-> [모델 테스트 & 평가] : Train set으로 학습한 model을 최종적으로 Test set으로 평가
의 순서로 진행됩니다! (오늘을 제외한 앞으로 대부분의 실습은 위의 과정을 따를테니 잘보고 익혀주세요)
이때 모델링은
사용하기 좋게 전처리된 데이터를 분할하여 모델을 학습하는 단계입니다.
앞으로 저희가 모델이 유의미한 결과를 도출해내는지 ! 학습이 잘 된 모델인지 ! 아는 것이야말로
머신러닝에서 빠져선 안될 핵심이라고 할 수 있죠
따라서 모델링과 친해진다면 다른 프로세스 친구들과도 친해진 기분이 드실 것 같아서 가장 첫 주제로 가져와보았습니다:) 이 시간 이후로는 데이터 수집 단계부터 차근 차근 알려드릴 예정입니다 !
그렇다면, 이제 모델링을 위한 프로젝트 생성 및 모델 생성을 해볼게요.
Brightics Studio 실행 + 프로젝트 생성
1단계

Brightics Studio를 실행해서 새로운 프로젝트와 모델명을 입력합니다.
저는 왼쪽 상단의 + 기호를 눌러 <Basic 1> 이라는 이름으로 프로젝트를 만들어주었어요.
그 후 create a model 부분에 'NEW'를 클릭하여 새로운 모델도 만들어줍니다.
이때 템플릿은 default 템플릿을 선택해주었습니다.
ㄴ오늘은 브라이틱스 AI 튜토리얼 영상 속에 나오는 iris모델을 사용해볼 예정입니다 !
모델링을 해보자
1. 데이터 확인하기 - Load

데이터 load 중
Brightics Studio내에 저장되어 있는 sample_iris.csv 데이터를 불러와주었습니다.
먼저, 데이터를 분석하기 전 데이터의 종류와 형태를 보는 것이 중요해요.
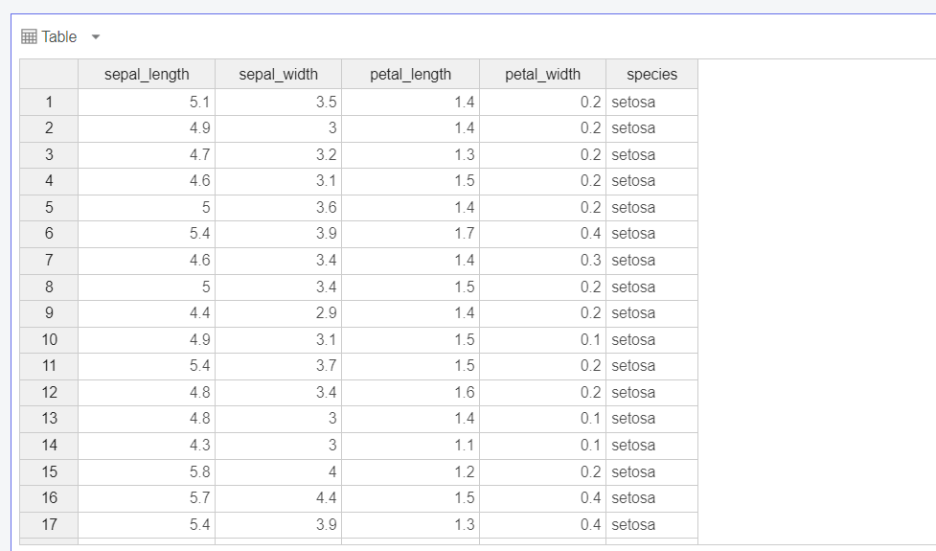
데이터 형태 확인
* 아이리스(붓꽃) 데이터*
붓꽃의 3가지 종(setosa, versicolor, virginica)에 대해 꽃받침sepal과 꽃잎petal의 길이와 너비를 정리한 데이터
컬럼명 : speices(종) / sepal.width(꽃받침의 너비) / sepal.length(꽃받침의 길이) / petal.width(꽃잎의 너비) / petal.length(꽃잎의 길이)
*데이터 분석 기법*
data set에 4가지 특성을 통해 Iris 꽃의 종류를 예측하는 것이기에
=>분류(classification) 문제!
2. Statisic Summary


통계량 구해주기 / 그룹화하기
추가로, 새로운 함수인 statistic summary를 해주었습니다.
[Select Function] 창 -> [statistic summary]검색 후 클릭
이때, Input Columns로 원하는 열을 지정해주고
Target statistic에서 구하고자 하는 통계계산방식을 선택해줍니다.
또한 Group BY 옵션을 통해 종별로 통계값을 구할 수 있습니다
ㄴ함수를 익히는 단계이니 다들 맘편히 아무거나 클릭해보셔요들 ~^^
3. Modeling
자 이제 Train data 와 Test data로 나누어서 모델링해보는 작업만 남았습니다 !
이때, 모델을 생성하는 방법은 다음과 같아요. (이 이외에도 정말 많답니다 ㅎㅎ)
1 ) Decision Tree 2) Random Forest 3) Logistic Regression
이 중에서 Decision Tree 방법을 통해 모델링 진행보았습니다.
의사결정 나무는 if~else와 같이 특정 조건을 기준으로 O/X로 나누어 분류/회귀를 진행하는 tree구조의 분류/회귀 데이터마이닝 기법입니다.
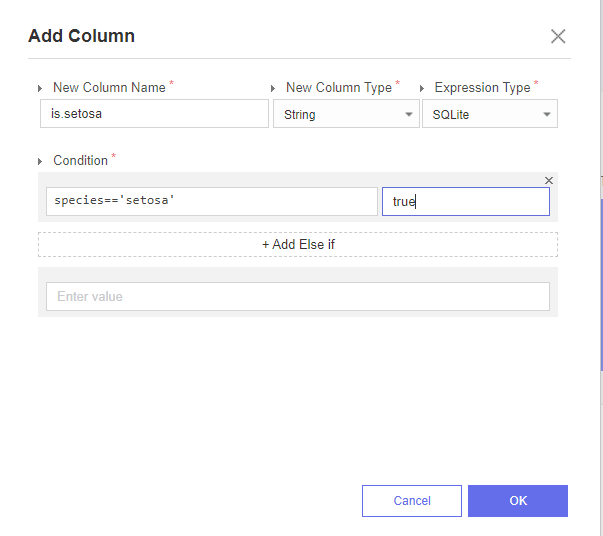
add column
따라서 모델을 split하기 전에 training 시키기 위한 작업을 거쳐줍니다.
add column 함수를 이용해서 if species 가 setosa인 것만을 구분해주려고 합니다.
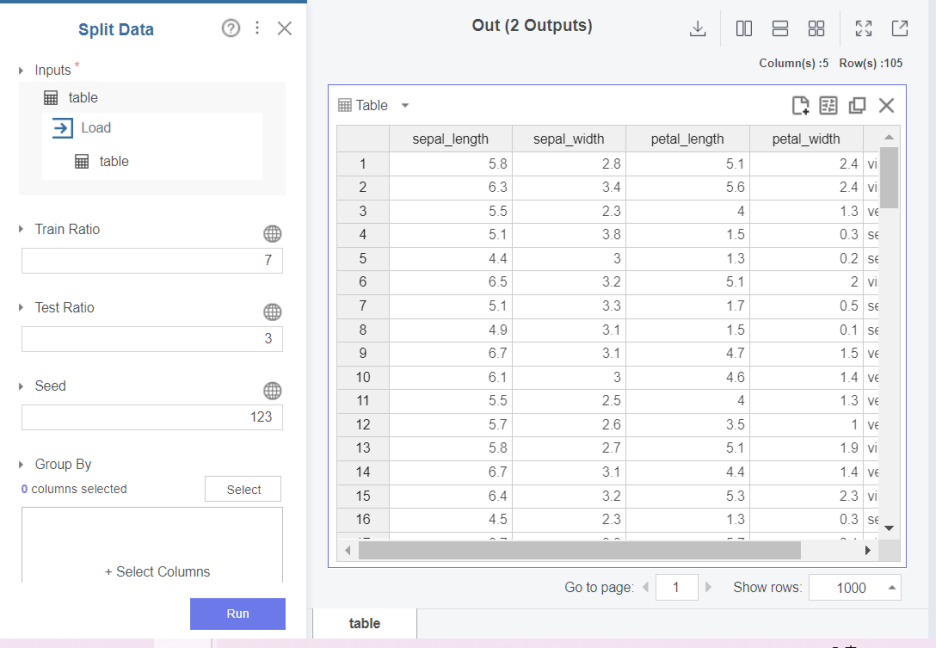
split data
먼저 Train data 와 Test data로 나누기 위해 7:3 비율로 split data를 해줍니다.
이때 만들어진 train data는 이후 decision tree classificaition에서 이용됩니다.
그리고 test data는 모델의 정확도를 확인하기 위한 용도로 사용됩니다.


그 후 decision tree classificaition에서 train data를 확인해줍니다.
이때 결과를 통해서 중요변수는 petal_length petal_width임을 알게 되었습니다.
따라서 다시 한번 더 진행해주어 decision tree를 만들어주세요 !

이제 test data를 사용할 차례입니다.
Decision tree classificaion predict 함수를 통해 decision model을 예측해줍니다.
이때 150개의 데이터 중 30%에 해당하는 45개의 데이터를 예측해준 결과값이
prediction 열, 그리고 그 확률은 probabilty 열로 생성됩니다.


드디어 마지막 !
Evaluate classification 함수를 통해 최종 예측값의 정확도를 확인해보겠습니다.
setoso 꽃을 예측한 값이 실제 setosa꽃이 맞을지 확인할 결과,
정확도는 0.93으로 높은 값이 나왔네요 :)
예측한 꽃이 실제 해당 꽃으로 나오는지 분류문제를 이렇게 풀어보았습니다.
어떠신가요! 이제 모델링과 조금은 친해진 기분이 드시나요?
앞으로 자주 볼 친구이니 미리 살짝쿵 소개드려보았어요 ~
바로 뒤이어서 ..
두번째 , 세번째 방법으로 2) Random Forest 3) Logistic Regression을 알려드리려 했으나 ..
분량 조절 실패로 ^^... 다음 advanced level 포스팅에서 더욱 자세히 다루어보겠습니다!!!
빨리 후다닥 만들어 오겠습니다.. 조금만 기달려 ~
*해당 게시글은 Brightics 서포터즈 활동의 일환으로 작성된 포스팅 입니다.
게시글 관련 문의 및 소통을 원하신다면 아래 댓글로 남겨주세요
브라이틱스 사용 중 문의사항은
brightics@samsung.com으로 연락주세요 :)
'대외활동 > Brightics 서포터즈' 카테고리의 다른 글
| [Brightics | 실습] 서울시 공유 자전거 이용자 & 이용시간 분석:: EDA, Chart 생성, 레포트 작성 (0) | 2021.06.22 |
|---|---|
| [Brightics | 실습] 브라이틱스로 본 서울시 공유 자전거 현황 :: 데이터 전처리편 (0) | 2021.06.15 |
| [삼성 SDS] Brightics 서포터즈 2기 발대식 후기 (0) | 2021.06.15 |
| [삼성 SDS] Brightics Studio 설치 가이드라인 : 회원가입, 설치 및 실행 (0) | 2021.06.08 |
| [삼성 SDS] Brightics A.I 둘러보기 : 회원가입부터 Trial 체험 솔직 후기 (0) | 2021.06.08 |