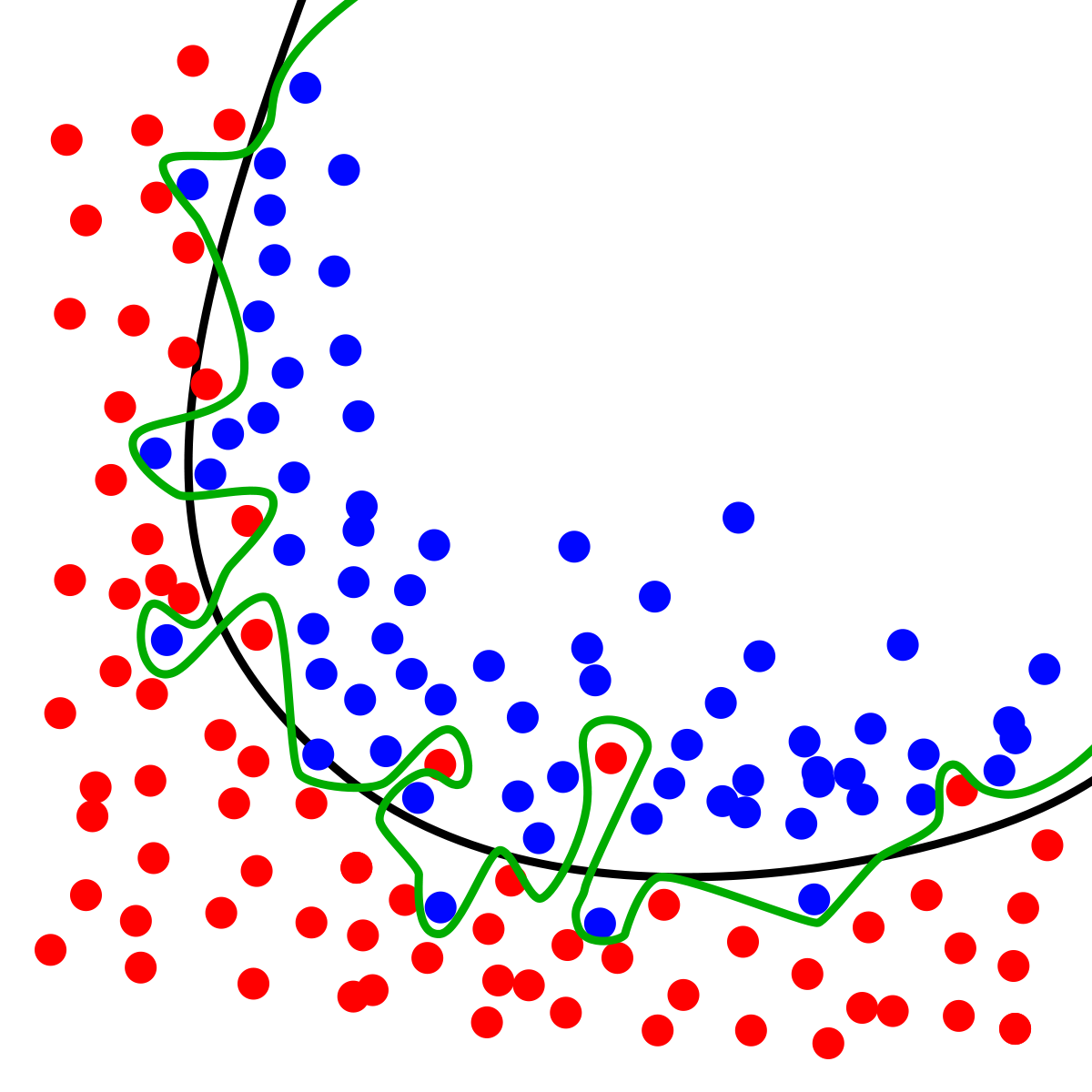
07. 과적합(Overfitting)과 정규화(Regularization) ❕ 오버피팅을 조심하자 ❕ (feature 수가 너무 많아서와 같은 이유로) 모델이 복잡해 variance가 커진 것을 오버피팅 overfitting 이라고 부른다. 우리가 모델링을 할 때 가장 두려워하는 것이 바로 오버피팅일 것이다. train set에만 정확하고 최종적인 목표인 test set에서는 성능이 낮게 나오면 말짱도루묵이기 때문이다. 물론 train set에서 성능이 잘나오면 엄청나게 나쁜 모델이 탄생하진 않겠지만 그래도 우리의 목표는 test set에도 만족하는 일반화를 이루어내야한다는 점 !! 여기서 짚고 넘어가야 할 점은, 우리의 손실함수인 mse를 최소화하려고 할 때 bias와 variance 사이에 trade..