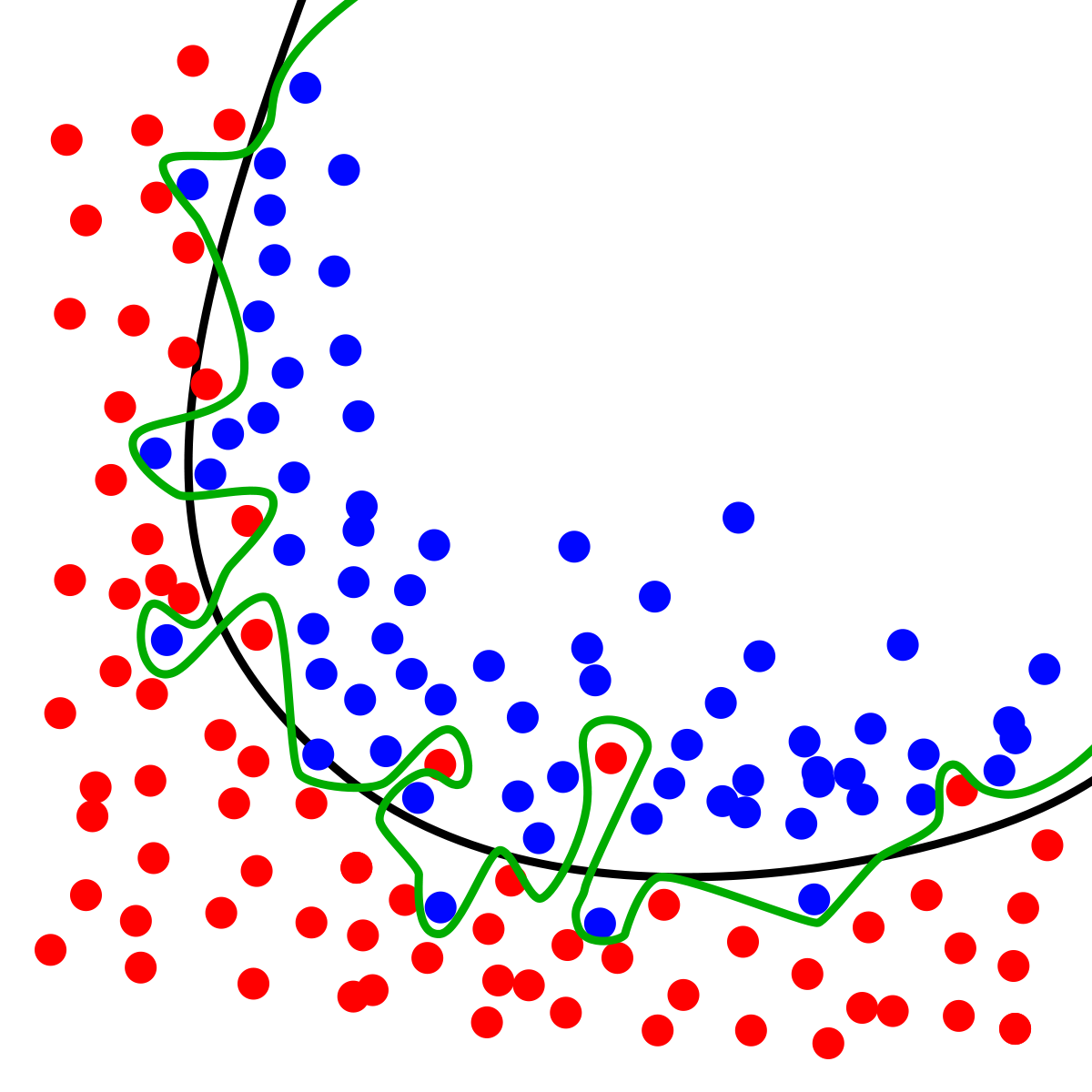
07. 과적합(Overfitting)과 정규화(Regularization) 07. 과적합(Overfitting)과 정규화(Regularization) ❕ 오버피팅을 조심하자 ❕ (feature 수가 너무 많아서와 같은 이유로) 모델이 복잡해 variance가 커진 것을 오버피팅 overfitting 이라고 부른다. 우리가 모.. uumini.tistory.com 앞서 오버피팅과 정규화의 원리에 대해 알아보았다. 이번엔 정규화 중 L2-norm 형식을 살펴보자. ❕ 정규화 (1) - L2 정규화 : Ridge regression ❕ L2 정규화는 "회귀 계수 β에 대한 제곱값"에 대한 제약조건을 취한 것이다. 그리고 이를 선형 회귀모델에 적용한 것이 Ridge regression이다. Ridge regre..