RNN의 한계점
1) Vanishing / Exploding Gradients
가중치를 업데이트 시키는 Back Propagation Through TIme(BPTT)과정에서, time step이 하나씩 늘어날 때 마다, chain rule 연산도 늘어나게 된다. 아래 그림은 hidden state 벡터에서의 편미분 값을 보여주고 있다.
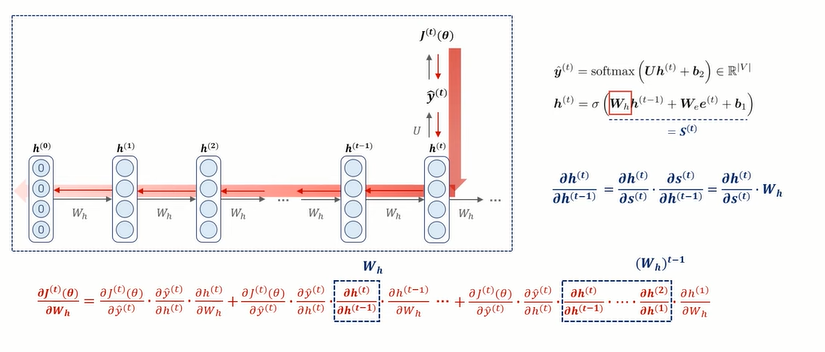
이때 편미분 횟수만큼 W_h가 곱해지고 있는 모습 !!
⇒ 이 과정에서 RNN의 문제점 발생
- 𝑊ℎ가 작을 수록(< 1) 반복적으로 곱해지는 값이 0에 가까워져 gradient vanishing
gradient descent를 구하기 위해서 weight로 미분해주는 과정에서, chainrule을 사용해서, 미분값을 여러 개를 곱해주게 되는데, 이때, 만약에 입력 sequence가 긴 sequence가 들어가게 된다면, 을 가정해보자. / 이때, 만약 미분값이 1보다 작은 값으로 계속해서 서로 곱해진다면 0에 매우 근접한 값이 나오게 되면서, 새로운 weight 값은 기존의 weight값과 거의 차이가 없다. 즉, 아무리 학습을 길게한다고 해도, weight값이 거의 변하지가 않는다. 따라서 학습이 길어지고 비효율적이게 된다
- 𝑊ℎ가 클 수록(> 1) 반복적으로 곱해지는 값이 기하급수적으로 커져 gradient exploding
만약에 미분값이 1보다 크다면, 반대로 상당히 값이 커지겠죠. 그러면, 이 새로운 weight value는 기존의 weight value와 상당히 달라짐- 즉, 이 weight값이 왓다리 갓다리 함. 그래서 training이 한 곳으로 모아지지 못하게 되는 문제 발생
- 따라서, 파라미터 업데이트가 어렵거나 불가능한 문제 발생 !!
- 이건 rnn의 특성 상, 동일한 가중치를 공유하고 있기 때문에 발생하는 필연적인 문제

이때, gradient vanishing 문제를 조금이라도 완화하기 위해서 RNN은 hidden state을 도출하는 활성화함수로, sigmoid함수 말고, tanh 을 사용
2) Long Term Dependency 보장 x
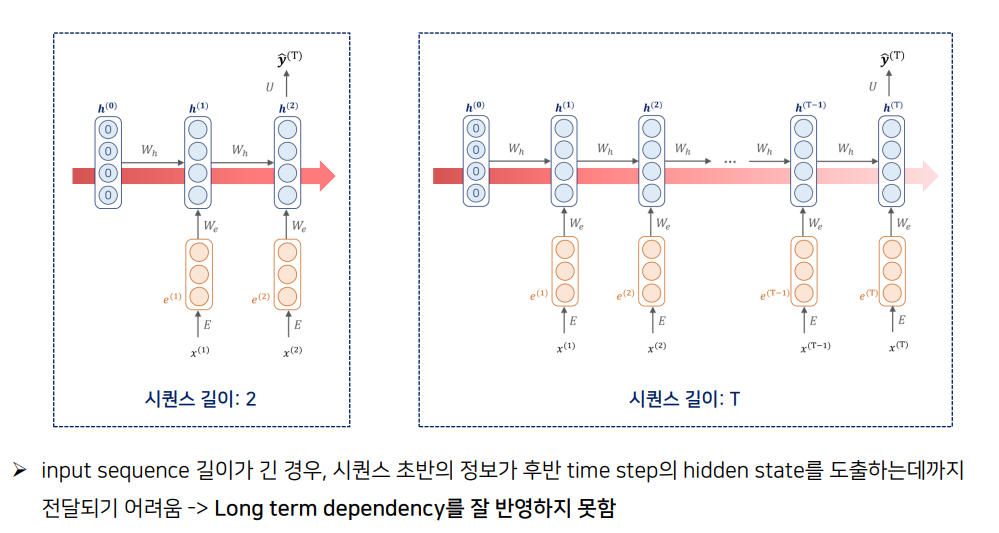
RNN은, 문장의 길이가 길면 gradient를 구해주기 위해 미분값들을 chain rule에 의해 곱해줄 때,
1) 1보다 작으면 gradient vanishing
2) 1보다 크면 gradient exploding 문제 발생해서, 초반의 정보들과는 다른 가중치 업데이트가 진행됨.
⇒ 즉, Long tern dependency 반영x
⇒ LSTM 등장
'데이터 스터디 > DL' 카테고리의 다른 글
| [논문 읽기] Sequence to Sequence Learning with Neural Networks (Seq2Seq) (0) | 2023.11.14 |
|---|---|
| [논문 읽기] Generating Sequences With Recurrent Neural Networks (LSTM) (0) | 2023.11.14 |
| CNN - convolution 연산 이해하기 (0) | 2023.11.10 |
| 07. Back Propagation - 역전파 이해하기 (0) | 2023.11.10 |
| [코드 분석] Bag of Words for IMDB movie review (1) | 2023.02.01 |