Seq2Seq(Sequence-to-Sequence)
- 입력으로서, sequence of item을 받고 아웃풋으로도 sequence를 내어줌.
- 입력의 sequence of item 개수와 출력의 sequence of item개수는 같을 필요는 전혀 없다 ! ex) 입력을 3단어로 구성된 문장이어도, 4단어로 구성된 문장이 나올 수 있음
- 가변적인 길이의 source 문장의 문법적, 의미적 특징을 고정된 크기의 벡터로 압축하는 아키텍처
- Encoder와 Decoder로 구성되어 있으며, encoder는 문장을 압축하는 역할, decoder는 문장을 생성하는 역할
- 입력된 정보를 어떻게 저장할 것이냐(인코더) → 어떻게 풀어서 반환할 것인가(디코더)

Encoder의 역할
- 가변적인 길이의 source 문장의 문법적, 의미적 특징을 고정된 크기의 벡터로 압축하는 역할
- 각각의 input sequence에 있는 item을 다 compile해서 하나의 벡터로 표현 ⇒ context벡터 생성
- GRU 아키텍처를 활용하여 압축 (입력으로 임베딩 벡터와 이전 시점의 hidden vector받음)인코더는 context vector를 디코더에게 넘겨줌
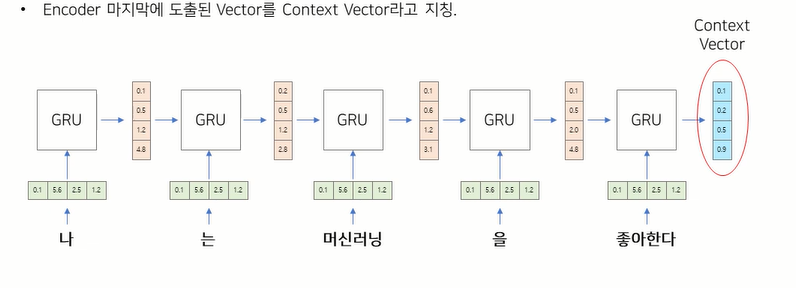
- 각각의 입력이 들어갈 때마다 hidden state가 한 번 씩 업데이트되고, 최종적으로 모든 input이 들어온 다음, 가장 마지막 hidden state가 context vector가 되서 decoder로 전달됨.
Decoder의 역할
- 인코더에서 압축한 source문장의 context vector를 활용하여, target 문장을 생성하는 역할
- GRU아키텍처를 활용 + 입력으로 임베딩 벡터, 이전 시점의 hidden vector, context vector받음
- decoder는 인코더가 전달해준 가장 마지막 hidden state 벡터를 통해서 아웃풋을 만들어냄.
- 인코더에서는 입력을 압축만 했다면, 디코더는 문장을 출력해야함.

- Decoder 계산 시, 매 시점 정보를 생성하는 과정에서, 입력과 이전 시점의 hidden 벡터 뿐만 아니라 context vector가 추가된 형태임 !
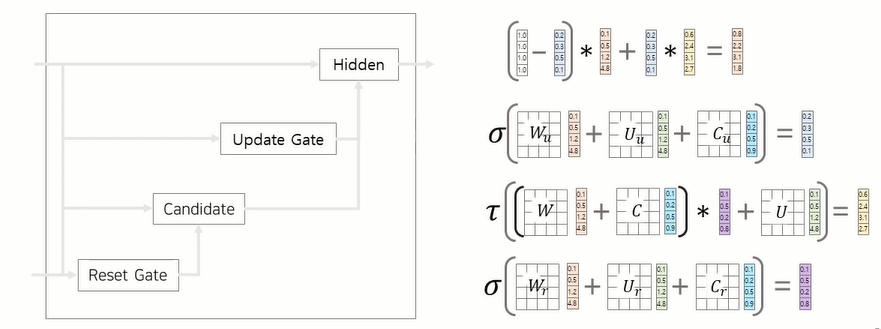
- 그렇다면, 어떻게 문장을 생성하게 될까 ?
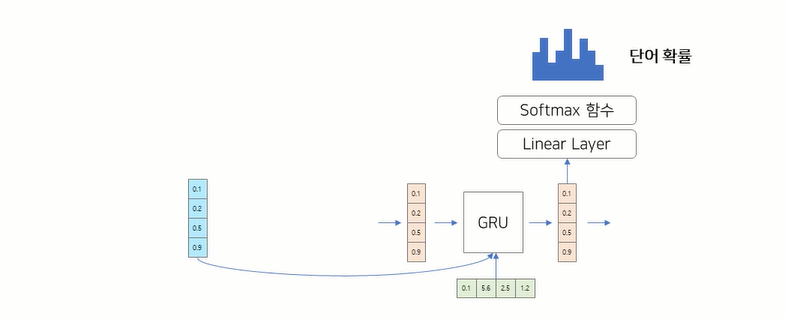
- hidden vector에서 최종적으로 linear layer를 추가해서, vocab사이즈만큼의 vector를 생성
- 최종 vector에 softmax함수를 취하면, 특정 단어가 나올 확률값이 나오고, 확률값이 가장 큰 단어를 선택하면 됨
학습 구조
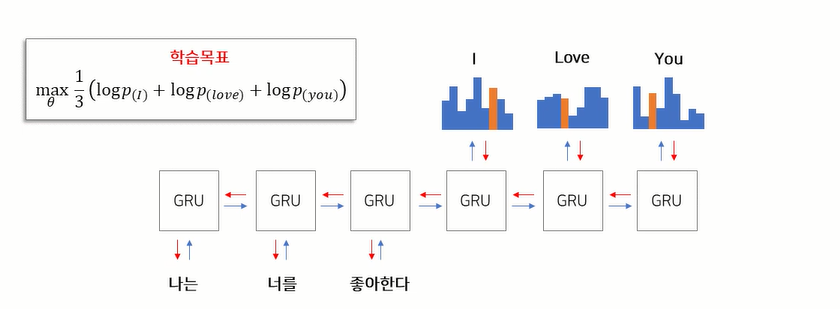
- target 문장을 label로 활용하여, decoder로부터 나온 확률을 기반으로 학습
- target문장의 cross entropy값을 계산하고, gradient descent 방식으로 학습
- 디코더뿐만 아니라, 인코더에 있는 GRU의 가중치를 동시에 학습
- 문제는, 인코더가 가져온 context vector는, 가장 뒷쪽의 item에 훨씬 큰 영향을 받게되고, 앞쪽 item은 영향을 적게 받게 됨 ⇒ 따라서 이를 해결하기 위해 lstm, gru가 등장
- 어느정도는 완화해줄 수 있지만, 완벽하진 않음. 따라서 attention을 통해, 아주 긴 item(=sequence)에서 주목해야 할 파트에 connection, 가중치를 줌.
'데이터 스터디 > DL' 카테고리의 다른 글
| [논문 읽기] Attention IS All You Need (Transformer) (0) | 2023.11.15 |
|---|---|
| [논문 읽기] Neural Machine Translation by Jointly Learning to Align and Translate (Attention) (0) | 2023.11.14 |
| [논문 읽기] Generating Sequences With Recurrent Neural Networks (LSTM) (0) | 2023.11.14 |
| RNN - 역전파와 한계점 (0) | 2023.11.10 |
| CNN - convolution 연산 이해하기 (0) | 2023.11.10 |