Transformer
0) Architecture


배경
- seq2seq은 sequence가 길어지는 경우 앞부분의 gradient를 잘 반영못한 context vector를 이용하게 돼 기울기 소실 문제 발생
- 문맥 벡터 하나로는 모든 정보를 담기 힘듦.
- ⇒ attention mechanism을 이용하자

- encoder에서 모든 hidden state를 보존 ⇒ 내적값을 구해서 alignment score 구하는 방식 채택
1) Input into Encoder
input embedding

- 문장의 토큰을 원-핫인베딩으로 인코딩 후 가중치행렬 w와 내적(=인덱싱)함
- 이때 토큰은 sequential(x) parallel(한꺼번에) 입력되는 형태이므로 순서정보가 보존되지 않아, positional encoding 스텝이 추가됨.
- Parallel : 입력된 문장을 병렬로 한번에 처리한다는 특징
- RNN을 사용하지 않고도 시계열 데이터를 처리하기 위해 트랜스포머는 (각 단어의 임베딩 벡터 + 단어의 위치 정보) 를 모델의 입력으로 사용.
Positional Encoding
- 조건1. 모든 위치값은 시퀀스의 길이나 Input에 관계없이 유일한&& 동일한 식별자를 가져야 한다.
- 조건2. 모든 위치값은 너무 크면 안된다. (위치값이 너무 커져버리면, 단어 간의 상관관계 및 의미를 유추할 수 있는 의미정보 값이 상대적으로 작아지게 되고, Attention layer에서 제대로 학습 및 훈련이 되지 않을 수 있다.)


- pos = 입력 문장에서 임베딩 벡터의 위치(문장 중 몇 번째 단어인가?)
- i = 임베딩 벡터 내의 차원의 인덱스(단어의 분산표현 중 몇 번째 차원인가? )
- 홀, 짝에 따라 포지셔널 인코딩 함수에서 sin, cos을 사용.
더보기
class PositionalEncoding(nn.Module):
"""
compute sinusoid encoding.
"""
def __init__(self, d_model, max_len, device):
"""
constructor of sinusoid encoding class
:param d_model: dimension of model
:param max_len: max sequence length
:param device: hardware device setting
"""
super(PositionalEncoding, self).__init__()
# same size with input matrix (for adding with input matrix)
self.encoding = torch.zeros(max_len, d_model, device=device)
self.encoding.requires_grad = False # we don't need to compute gradient
pos = torch.arange(0, max_len, device=device)
pos = pos.float().unsqueeze(dim=1)
# 1D => 2D unsqueeze to represent word's position
_2i = torch.arange(0, d_model, step=2, device=device).float()
# 'i' means index of d_model (e.g. embedding size = 50, 'i' = [0,50])
# "step=2" means 'i' multiplied with two (same with 2 * i)
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
# compute positional encoding to consider positional information of words
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 128, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# it will add with tok_emb : [128, 30, 512]- ❓왜 cos, sin함수를 사용하는가❓
- ❓ 왜 Input Embedding과 Positional Encoding 간의 연산은 summation일까 ❓
- (아래 블로그에 설명이 매우 잘되어있다!)
트랜스포머(Transformer) 파헤치기—1. Positional Encoding
트랜스포머 Transformer Attention is All You Need Postional Encoding
www.blossominkyung.com
2) Encoder
하나의 인코더 층은 ‘멀티 헤드 셀프 어텐션’ 과 ‘포지션 와이즈 FFNN’라는 두 개의 서브층으로 구성된다.
2.1. Multi - head Self Attention
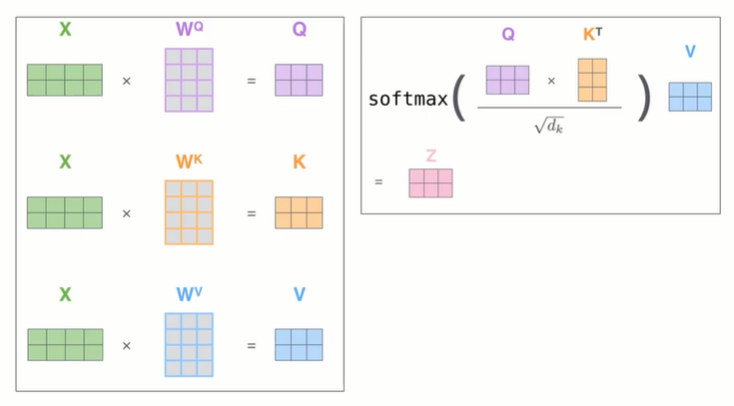
- 인코더의 특정 임베딩 벡터가 다른 임베딩 벡터들과 얼마나 연관이 있는가? 를 구하기
- Q, K, V는 입력 문장의 단어 벡터들이다.
- Q, K, V의 차원은 원래의 차원 d_model을 병렬 어텐션 수 num_heads로 나눈 값이 된다.
- 전체 key 중 Query에 대해 각 key들이 지니는 비중(=유사도)를 계산
- Query와 가장 관련이 깊은 key의 value위주로 값을 가져옴
Attention Score
- Linear 연산을 통해 그림과 같이 동일한 query, key, value를 얻게 된다. 그후 다음 연산으로 먼저 query와 key행렬을 내적한다. 그럼 그 결과 아래 그림처럼 Attention Score를 얻게 된다.

- Attention Score란 query와 key 행렬의 행렬곱으로 이때 행렬곱은 행렬 간의 유사도를 의미하기에 Attention Score는 query와 key 사이의 유사도인 유사도 행렬를 나타낸다.
- 이렇게 구한 Attention Score를 훈련을 시키고 나면 자기 자신과 매핑되는 값이 가장 크고 그 다음으로 유사한 값이 크다는 것을 알 수 있다.
- Scaling : 스케일드-닷-프로덕트-어텐션 - 어텐션 스코어를 sqrt(차원의 크기)으로 나눠준다.
- 트랜스포머는 이러한 Self-Attention을 병렬로 h번 학습시키는 Multi-Head Attention 구조
=> 다양한 유형의 종속성을 포착할 수 있어 표현력이 향상되는 장점임
- ❓루트 d_k로 나누는가❓(향후 공부)
패딩 마스크
- 어텐션 스코어 행렬에서 key에 패딩 토큰이 있으면(<pad>열이 있으면) 그 열에 매우 작은 음수 할당
- 리마인드 : q와 T(k)의 행렬곱인 어텐션 스코어 행렬을 softmax에 넣어 만든 어텐션 가중치 행렬과 v를 곱해 어텐션 값을 만드는데, softmax 함수를 지날 때 엄청 작은 값이 있으면 해당 열이 0이 된다.
- 패딩토큰은 의미가 없으니 가중치를 안 준다!

2.2 Feed Foward Network(FFN)

- 두 개의 밀집층의 중첩
- 밀집층 1 : d_ff개의 뉴런을 가지고 Relu 함수가 활성화 함수.
- 밀집층 2 : d_model개의 뉴런을 가지고 활성화함수는 따로 없다.
→ 밀집층 2까지 거치면 input의 형상과 형상 동일. - FFN의 파라미(W,b)는 같은 encoder layer내에서는 동일한 값을 가진다.
잔차연결 & normalization

- 잔차 연결 : 입력 x가 서브층을 거칠 때마다 그 출력에 입력을 더해준 것을 출력으로 한다.
- 층 정규화 : 잔차 연결의 출력을 마지막 차원(d_model)을 기준으로 평균, 분산을 구해 정규화.

- 역전파시에 미분값 안정화시키는 효과 있다 함.
- 분모가 0이 되지 않도록 충분히 작은 양수 eplison 설정하기
- 이후 초기값이 각각 1, 0인 벡터 감마와 베타를 설정하여 다음과 같이 계산
- 케라스에서 LayerNormalization() 제공.
3) Decoder
트랜스포머의 디코더는 3개의 서브층이 있다 : 셀프어텐션 - 인코더/디코더 어텐션 - 포지션 와이즈 FFNN
Masked Multi - head Self-Attention

- 트랜스포머는 문장 행렬을 한 번에 입력받으므로 미래의 단어도 참고하는 현상 발생(좋은거아님)
—> 못 보게 해야한다 : 룩 어헤드 마스크. - Q와 K (감소된 차원의 문장 행렬 )를 행렬곱한 어텐션 스코어 행렬을 보자.
- 각 행을 보면, 자신의 순서 이하의 단어만 참고하도록 마스킹을 하면 디코더가 미래의 단어(정답)을 훔쳐보고 단어를 예측하지 않도록 할 수 있다
- band_part()를 이용해 행렬의 대각 부분을 기준으로 0을 만들어주고 1에서 빼면 마스킹이 된다.
정리하자면
1) padding token의 위치에 대한 masking
2) attention score로 가중치를 구할 때 대상 토큰이 이전 시점의 토큰을 참조하지 못하도록 masking
Decoder의 Multi-head Attention
디코더의 문장 행렬이 인코더의 문맥을 참고하도록 병렬 어텐션 진행.
FFN
인코더에서와 같이 각 서브층별로 잔차 연결 & 층 정규화를 거친다.
4) Output
- Linear layer 는 fully-connected NN 으로 output 벡터를 그 보다 훨씬 큰 size 벡터로 투영시킨다
- size가 늘어난 벡터를 softmax를 통해 확률값으로 변환시키고 가장 높은 확률을 가진 셀의 해당하는 단어가 하나의 위치마다 하나씩 출력된다
