GPT1
Abstract
1. Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification.
2. large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce
3.We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task.
- 2018년 OPENAI에서 발표한 논문으로, gpt는 semi-supervised language model로서 labeled data의 부족으로 어려움을 겪고 있는 supervised nlp task들을 위해 새로운 해법을 제시함.
- nlp는 텍스트 의미 추론, 질문 응답, 의미 유사성 평가, 분류 등 다양한 작업으로 이루어진 포괄적인 범위를 다룸.
- unlabeled data는 많고, labeled data는 부족하여 성능을 충분히 내지 못하고 있는 상황임.
- 우리는 언어 모델을 다양한 unlabeled text에 대한 generative pre-training 을 통해 큰 이익을 얻을 수 있음을 보여주고, 각 특정 작업에 대한 discriminative fine-tuning을 이어 나가는 것으로 큰 성과를 얻을 수 있음을 입증함.
Background
1. supervised / unsupervised
- supervised learning : labeled data를 학습에 사용
- unsupervised learning : unlabeled data를 학습에 사용
- semi supervised learning : labeled & unlabeled data를 학습에 사용
2. generative / discriminative

- generative
- 개념 : 데이터를 생성하기 위한 모델로, 데이터가 생성될 확률인 p(x,theta)
- 주어진 training data를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델
- 라벨정보가 없어도 모델 구축이 가능
- gpt에서 unlabeled data를 사용해서 pre-training학습을 진행
- discriminative
- 개념 : 데이터 가 주어졌을 때 레이블 가 나타날 조건부확률 를 직접적으로 반환
- 의 label을 잘 구분하는 decision boundary를 학습하는 것이 목표
- gpt에서 fine-tuning하는 과정에서 쓰임.
3. transformer
- 기존의 rnn기반의 인코더-디코더 구조는 long-term dependency 문제가 발생한다는 점에서 rnn대신 attention을 사용
- 문장의 순서정보를 알려주기 위한 포지셔널 인코딩을 진행
- encoder는 ‘멀티 헤드 셀프 어텐션’ - ‘포지션 와이즈 FFNN’라는 두 개의 서브층으로 구성
- decoder는 'masked 셀프 어텐션' - '인코더/디코더 multihead 어텐션' - '포지션 와이즈 FFNN ' 으로 구성
Introduction
- 대부분의 딥러닝 모델은 labeled data로 지도학습을 진행했기 레이블링이 필요하지만, 구할 수 있는 대부분의 데이터는 unlabeled data였다라는 한계가 존재
- 본 논문에서는 unlabeled data를 활용해 모델을 학습시키고, 이후 fine-tuning만으로 효과적인 transfer를 하게 함으로써 높은 성능을 달성할 수 있다는 것을 입증
- unlabeled 데이터로 학습시키는 것은 두 가지의 challenge가 있음
- First, it is unclear what type of optimization objectives are most effective at learning text representations that are useful for transfer. 어떤 목적함수가 효과적인지 알수없음
- Second, there is no consensus on the most effective way to transfer these learned representations to the target task. 학습된 이 표현을 대상 작업에 어떤 방식으로 전이하는 것이 가장 효과적인지에 대한 공통된 의견이 없음
- 본 연구에서는 unsupervised pre-training과 supervised fine-tuning을 합친 준 지도학습 방식을 제안
- 대량의 unlabeled data와 task에 알맞는 labeled data가 있다고 가정하고, 해당 모델은 unlabeled data로 모델의 초기 파라미터를 학습하고, 이렇게 최적화된 파라미터를 다음 fine-tuning때 같이 학습시킴.
Framework
GPT모델의 프레임워크는 2가지로 나뉜다.
1) generative pretraning - unlabeled large corpus로 학습
2) discriminative fine-tuning - labeled data 활용하여 specific task에 학습
Unsupervised pre-training
- 학습을 위한 languge model로 multi-layer Transformer decoder를 사용했다
- 기존 트랜스포머의 구조에서 인코더-디코더 사이에 multi-head attention layer를 제외시켰다는 점
self attention과 feedforward 레이어로만 구성 - 트랜스포머의 base model 은 6 layers인 반면, GPT1은 12 blocks

- Objective function
where k is the size of the context window, and the conditional probability P is modeled using a neural network with parameters Θ. These parameters are trained using stochastic gradient descent
- input x와 최종 output이 나오는 과정
- 1. input x 토큰을 원-핫인베딩으로 인코딩 후(U) 가중치행렬 w와 내적(=인덱싱)함
: 즉, 임베딩 행렬 w에서 look-up을 수행하여 해당하는 벡터를 반환 - 2. 얻게된 단어벡터와 포지션임베딩 matrix를 더해줌 (summation 연산) → masked multihead를 거침
- 3. transformer 블록이 존재하는 만큼 처리하게되고,
- 4. 최종적으로 가장마지막 hidden state와 임베딩 행렬w의 transpose에 softmax를 취해서 각 토큰들의 확률값을 얻게 됨
- 1. input x 토큰을 원-핫인베딩으로 인코딩 후(U) 가중치행렬 w와 내적(=인덱싱)함
Supervised fine-tuning
- pre-train한 모델을 fine-tuning하는 과정
- 입력 토큰x로 이루어져 있는 labeled dataset C를 가지는 target task에 대해 파라미터를 조정

- 예측값을 얻기 위해 Pre-train된 transformer 모델의 마지막 블록의 activation 을 input으로 하는 linear layer를 추가
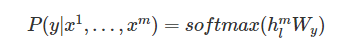
- 목적함수L2를 최대화하는 방향으로 학습
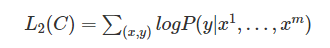
- 최종적으로는 L2와 함께 fine-tuning에 보조 목적(auxiliary objective)으로써 pre-train에 이용했던 목적함수 L1을 같이 써줌
- 지도학습 모델의 일반화를 향상시키고 모델이 빠르게 수렴하는 데 도움을 주는 것을 확인
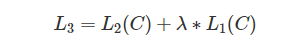
Task-specific input transformations
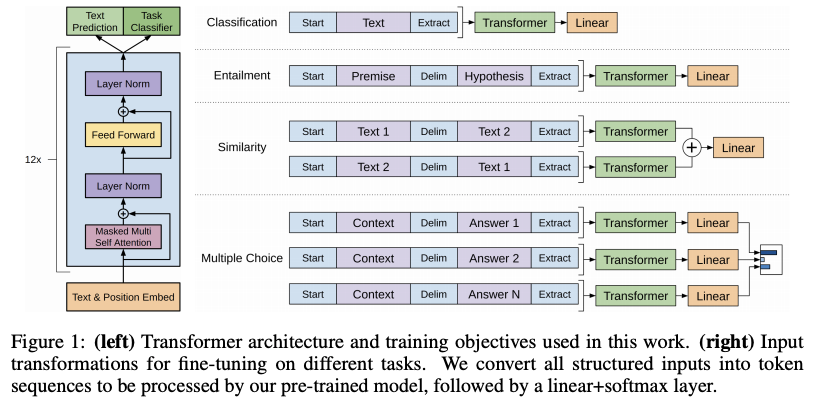
- 모든 변형은 무작위로 초기화된 start token < BOS (begin of sentence) 토큰 >와 end token< EOS (end of sentence) >를 포함
- Classification(분류) : text가 하나 들어가는 방식
- Textual entailment task(함의추론) : premise p와 hypothesis h 토큰 시퀀스를 delimiter token으로 concat
- semantic similarity(의미적 유사도 분석) : 가능한 문장 순서를 모두 포함하도록 입력 시퀀스를 delimiter token과 함께 수정
- Question Answering and Commonsense Reasoning: context document z와 question q, 가능한 답변 set이 주어지고 document context와 question을 delimiter token을 사용해 각 답변과 concat
Experiment
Dataset
- unsupervised pre-training
- - BookCorpus : 7천개 이상의 다양한 장르의 책 내용을 포함
- 1B word language model benchmark
- supervised fine-tuning

모델 구조
- masked self attention head가 포함된 Transformer의 decoder만 가져왔으며 12개 layer를 사용했다 (768 demensional states and 12 attention heads)
- Optimization으로는 learning rate가 조정된 Adam을 사용했고 batch size는 64, epoch은 100회 동안 훈련
- 인코딩은 BPE(Byte pair encoding)방식을, activation으로는 GELU(Gaussian Error Linear Unit)를 사용
- 전처리는 fifty liabrary를 이용했으며 구두점, white space를 표준화하고 spaCy tokenizer를 사용
- Fine-tuning에는 unsupervised pre-training에 사용한 하이퍼파라미터를 그대로 사용하되 learning rate를 6.25e-5로 수정하고 분류 task의 경우 dropout을 추가
- Epoch 3회, batchsize 32로 짧게 훈련했으나 대부분의 task에서 충분한 것으로 확인
NLI (자연어 추론)
- 두 문장의 관계를 수반하는 사이인지(entailment), 모순된 사이인지(Contradiction), 중립 관계인지(neutral)를 판단
- 이미지 캡션(SNLI), 정부 리포트(MNLI), 위키피디아 기사(QNLI), Science exams(SciTail), 뉴스 기사(RTE)로 각 task별 성능을 측정 및 비교
- RTE를 제외한 네 개의 데이터 셋에서 다른 모델보다 우수한 정확도를 달성
- improvements of upto 1.5% on MNLI, 5% on SciTail, 5.8% on QNLI and 0.6% on SNLI over the previous best results.
- On RTE, one of the smaller datasets we evaluate on (2490 examples), we achieve an accuracy of 56%, which is below the 61.7% reported by a multi-task biLSTM model.
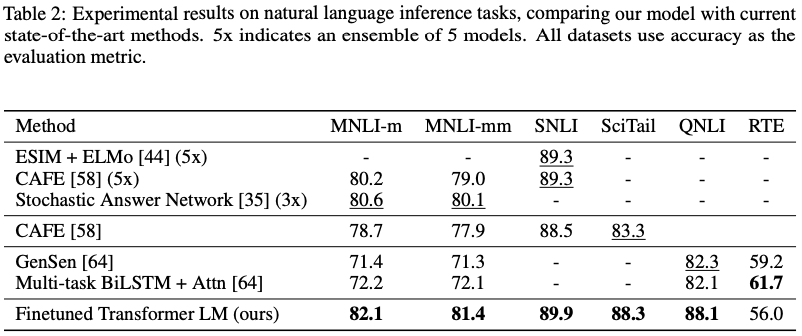
Question answering and commonsense reasoning (질문 대답 & 상식 추론)
- RACE : 중고교 영어지문 관련 지문 story cloze : 장문의 스토리글에 대한 적절한 엔딩글을 선별
- 모델 구조가 long-range contexts도 효과적으로 처리함을 보여줌
our model again outperforms the previous best results by significant margins - up to 8.9% on Story Cloze, and 5.7% overall on RACE.
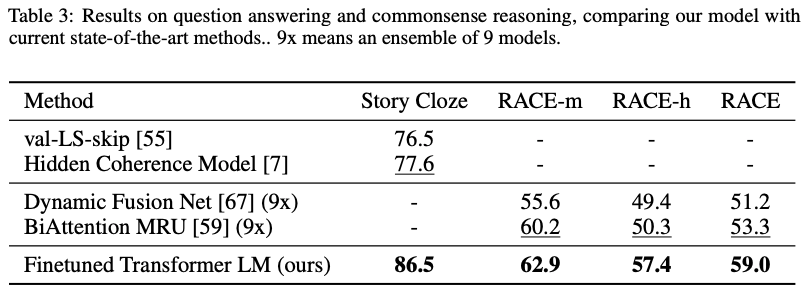
Semmantic Similarity (의미 유사성 분석)
- 입력된 두 개의 문장이 의미적으로 같은지를 예측
- 3개의 데이터셋 중 2 개에서 최고 성능을 달성
Classification
1) cola : 문법적으로 맞았는지 틀렸는지를 분류 2) sst : 문장의 sentiment를 분류하는 task

- 전체적으로 GPT 모델은 12개의 dataset 중 9개의 dataset에서 SOTA를 달성했으며, 5.7k의 데이터로 이루어진 작은 데이터셋부터 550k개의 데이터가 있는 큰 데이터셋까지 좋은 성능을 낸다는 것을 확인했다.
ANALYSIS
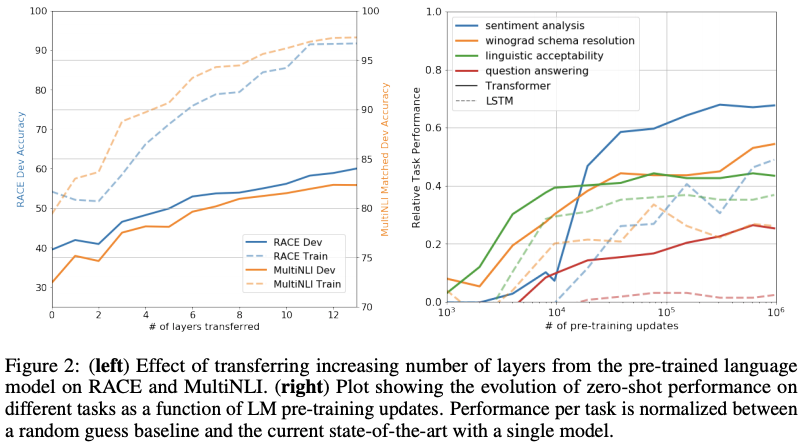
- 하단 왼쪽 그림은 MultiNLI와 RACE dataset에서 transfer된 layer의 개수에 따른 모델 performance에 대한 영향을 표현한 것
- 지피티의 디코더 블락을 증가시켰을 때 multiNLI와 RACE데이터셋에 train/test set에 성능이 향상되는 결과를 보임
- 그리고 layer12이후부터는 수렴 양상 보임
- 하단 오른쪽 그림은 zero shot (= 학습이 0이다 = fine-tuning을 하지 않았다 )의 성능을 lstm과 비교한 것
- generative model의 performance가 안정적이고 지속적으로 증가했으며 이를 통해 generative pre-training이 다양한 task에 관련된 정보를 학습하는데 도움을 준다는 의미
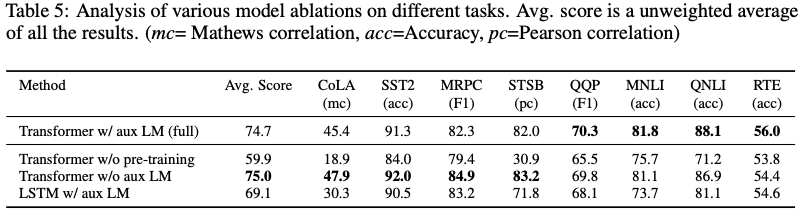
Ablation studies
- 세로축 method는 pre-train유무나 fine-tuning을 했는지이고, 가로축은 테스크에 쓰인 데이터셋을 의미
- cola와 sst2는 classification /mrpc, stsb, qqp : semantic similarity / mnli, qnli - nli
- pre-training없이 supervised learning만 진행한 경우에서는 모든 task에서 성능이 크게 하락
- 목적함수를 제거한 경우(=Transformer without aux LM), 성능이 오른 경우도 몇 있다는 점에서 큰 데이터 셋(=QQP, NLI, RTE)에서는 성능 향상에 도움이 되지만 작은 데이터 셋에서는 아님을 알 수 있음
- lstm으로 대체한 경우엔 맨 위에보다 낮은 걸로 보아서, 트랜스포머의 디코더 구조가 성능향상에 도움 됨
'데이터 스터디 > DL' 카테고리의 다른 글
| [논문 읽기] BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding (NAACL 2019) (0) | 2023.11.29 |
|---|---|
| BoW(Bag of Words), DTM (1) | 2023.11.29 |
| [Pytorch] 파이토치 Dataset, Dataloader (0) | 2023.11.17 |
| [Pytorch] 파이토치 nn.Module, nn.funcional (parameter, forward, backward연산) (0) | 2023.11.17 |
| [Pytorch] 파이토치 텐서(tensor) 기초함수, 연산 (0) | 2023.11.17 |