단어의 표현 방법

단어의 표현 방법에 대한 큰 체계를 한 번 정리해보자면, 지금까지 원핫인코딩, n-gram까지는 짚어봤다.
이들은 단어들끼리의 관계를 봐주진 않았고, 해당 단어 자체만 보고 특정값을 매핑하는 방법이었다.
되새겨보자면, 원핫인코딩의 경우에는 해당하는 자리에는 1을 쓰고 그 이외에는 0으로 벡터를 다 채워줬었다.
그리고 n-gram에서는 해당 단어구가 전체 훈련문장들 사이에서 몇 번 등장하냐 카운트해줬었다.
그리고 이들을 국소표현이라고 한다.
반대로 단어들 간에 중심단어를 두고 주변단어를 둬서 둘 사이의 관계로 표현하는 방법은 분산표현이라고 한다.
Bag of words
Bag of words란 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도수에만 집중해서 텍스트를 수치화하는 표현 방법이다.
이를 만드는 과정은,
1) 각 단어에 고유한 정수 인덱스를 부여한다. by 정수인코딩
2) 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 만들어준다.
=> 최종 출력값은, 단어의 빈도수를 각 단어의 인덱스에 기록해준 형태이다.
Bow를 직접 구현하 함수를 보면 더 직관적으로 쉽게 이해할 수 있다.
방법1. 직접 함수 정의
from konlpy.tag import Okt
okt = Okt()
def build_bag_of_words(document):
# 온점 제거 및 형태소 분석
document = document.replace('.','')
tokenized_document = okt.morphs(document)
word_to_index = {}
bow = []
for word in tokenized_document:
if word not in word_to_index.keys():
word_to_index[word] = len(word_to_index) # 정수 인덱싱
bow.insert(len(word_to_index) - 1,1)
else:
# 재등장하는 단어의 인덱스
index = word_to_index.get(word)
# 재등장한 단어는 해당하는 인덱스의 위치에 1을 더한다.
bow[index] = bow[index] + 1
return word_to_index, bowdoc = "고려대학교에는 안암역과 고려대역이 있다. 안암역 앞에는 오샬이 있고 고려대역 앞에는 고래돈까스가 있다. "
vocab, bow = build_bag_of_words(doc2)
print('vocabulary :', vocab)
print('bag of words vector :', bow)vocabulary : {'고려대학교': 0, '에는': 1, '안암역': 2, '과': 3, '고려대역': 4, '이': 5, '있다': 6, '앞': 7,
'오샬': 8, '있고': 9, '고래': 10, '돈까스': 11, '가': 12}
bag of words vector : [1, 3, 2, 1, 2, 2, 2, 2, 1, 1, 1, 1, 1]
코드를 보면, 한글을 대상으로 하고 있어서 okt형태소 분석기를 써준 모습이다.
bag of words를 구현하는 방식으로는 , 먼저 토큰화된 문서안에서 해당 단어를 찾아주고, 새로 등장한 단어라면 그 단어가 등장한 위치를 length로 받아서 정수를 부여해주고, 쭉쭉 단어 중복없이 인덱스를 설정해준다. 그리고 재등장하는 단어라면 else로 넘어가서 해당하는 인덱스 위치에 1을 더해서 빈도수를 카운트해준다.
그 결과, 우리의 문장이 “고려대학교에는 안암역과 고려대역이 있다. 안암역에 앞에는 오샬이 있고 고려대역 앞에는 고래돈까스가 있다” 일 때, 각 단어들별로 인덱스가 설정이 되어 있고, bag of words 벡터에는 최종적으로 그 인덱스에 해당하는 단어가 몇 번 등장했는지가 나온다.
여기서 고려대학교가 1번, ‘에는’이라는 단어가 3번, ‘안암역’이라는 단어는 2번 쭉쭉쭉 이렇게 저장이 되고 있다.
정리하자면,
Bag-of-words 벡터는 자연어 문장 내 등장한 단어의 빈도만을 고려하며, 단어의 등장 순서 정보는 고려하지 않는다.
자연어 문장을 bag-of-words 벡터로 표현하기 위해서,
1) 첫째로 Vocabulary의 각 단어를 one-hot 벡터로 변환하고
2) 자연어 문장 내 등장 단어들의 one-hot 벡터를 더한다
3) One-hot 벡터로 표현된 단어들 간의 코사인 유사도는 언제나 0이 된다
방법2. CounterVectorizer 클래스로 BoW 생성
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['you know I want your love. because I love you.']
vector = CountVectorizer()
print('bag of words vector :', vector.fit_transform(corpus).toarray())
print('vocabulary : ',vector.vocabulary_)bag of words vector : [[1 1 2 1 2 1]]
vocabulary : {'you': 4, 'know': 1, 'want': 3, 'your': 5, 'love': 2, 'because': 0}- CountVectorizer 함수는 길이가 2이상인 문자만 토큰으로 인식, 나머지는 제거
- 띄어쓰기만을 기준으로 토큰화하기 때문에 한국어에는 적용하기 어려움
bag of words vector : [[1 1 1 1 1 1 2 1 1 2]]
vocabulary : {'고려대학교에는': 3, '안암역과': 5, '고려대역이': 2, '있다': 9, '안암역': 4, '앞에는': 6, '오샬이': 7,
'있고': 8, '고려대역': 1, '고래돈까스가': 0}그리고 간편하게는 사이킷런에 들어있는 CountVectorizer로 생성하실 수 있다.
이때 CountVectorizer 함수는 길이가 2이상인 문자만=즉 다시 말해서 2글자 이상인 단어만 토큰으로 인식하고 나머지는 카운트해주지 않는다
그래서 해당 결과로 I 한글자는 등장하고 있지 않다. 그리고 토큰화가 띄어쓰기 기준으로 진행되기 때문에 한국어에서는 적용이 어렵다는 특징을 갖고 있다.
문서 단어 행렬(Document-Term Matrix, DTM)
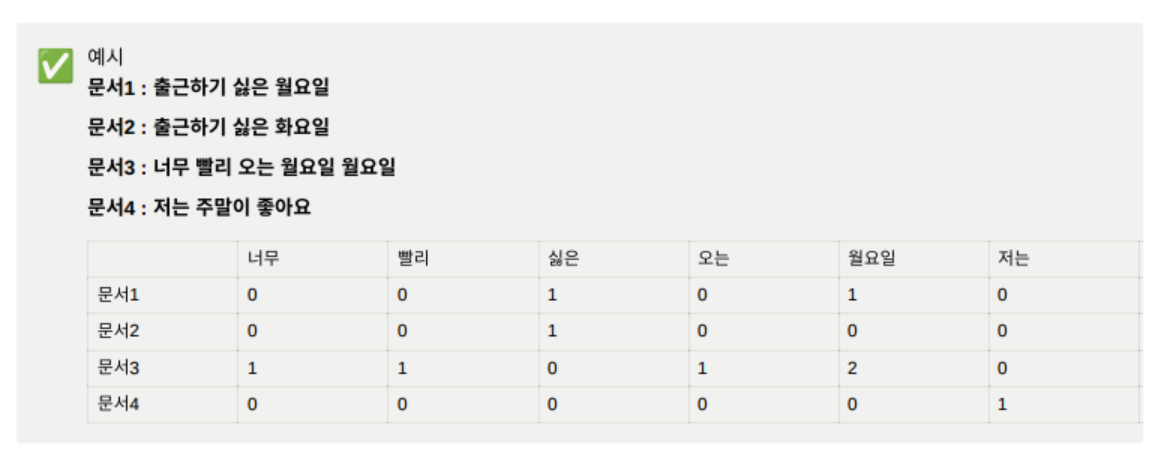
그리고 이 bag of words 벡터를 하나의 행렬로 만들어준 것을, document-term matrix, DTM이라고 한다.
각 단어들의 빈도를 행렬로 표현한 것이다고 보면 되겠습니다.
문서1, 문서2, 문서3, 문서 4를 한꺼번에 같이 처리해주고 잇고, 예시를 보면 문서 1은 출근하기 싫은 월요일을 정수인덱싱해서 빈도수를 행렬에 넣어주면 0,0,1,0,1,0,0,0,1,0,으로 표현이 된 것을 볼 수 있다.
하지만 여기서도 원핫인코딩이랑 똑 같은 문제가 발생한다.
바로 단어 집합의 크기가 벡터의 차원이 되기 때문에 남은 공간에 다 0이 들어가게 되어서 공간 낭비가 일어나고, 의미가 별로 없어지는 거다. 그리고 빈도 수로 접근을 하고 있기 때문에 우리가 만약에 지금 띄워쓰기 아니고, 형태소로 더 나노단위로 분석을 했다고 치면 조사나 어미 들은 모든 문서에서 자주 등장하긴 하지만, 중요한 단어는 아닌 것이다. 따라서 단어들마다 가중치를 둬서 문장의 유사도를 확인하고 서로 비교해주는 방법을 들어주기 위한 방법으로 TF-IDF기법이 등장하게 된다.