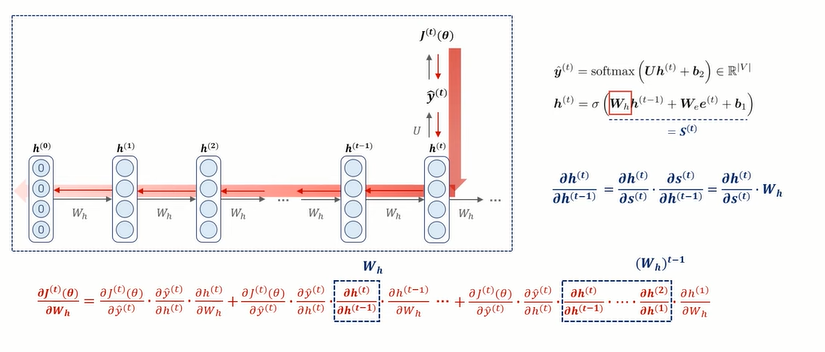
RNN의 한계점 1) Vanishing / Exploding Gradients 가중치를 업데이트 시키는 Back Propagation Through TIme(BPTT)과정에서, time step이 하나씩 늘어날 때 마다, chain rule 연산도 늘어나게 된다. 아래 그림은 hidden state 벡터에서의 편미분 값을 보여주고 있다. 이때 편미분 횟수만큼 W_h가 곱해지고 있는 모습 !! ⇒ 이 과정에서 RNN의 문제점 발생 𝑊ℎ가 작을 수록(< 1) 반복적으로 곱해지는 값이 0에 가까워져 gradient vanishing gradient descent를 구하기 위해서 weight로 미분해주는 과정에서, chainrule을 사용해서, 미분값을 여러 개를 곱해주게 되는데, 이때, 만약에 입력 seque..