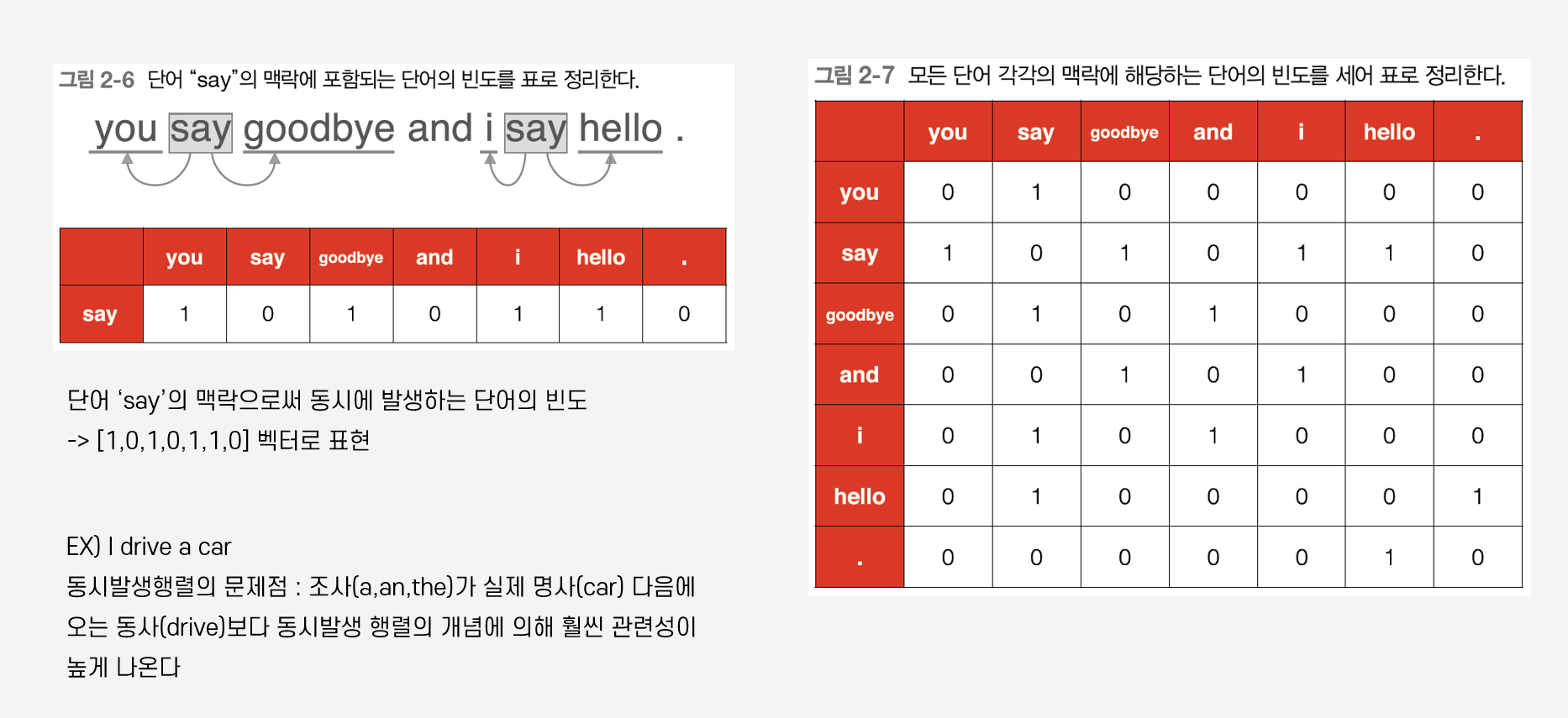
TF-IDF는 앞서 다루었던 DTM 행렬에서 행렬 내의 각 단어에 대한 중요도를 가중치로 삼아주는 기법이다. 따라서 TF-IDF는 주로 문서의 유사도를 구해서 추천시스템을 만들거나, 검색 결과 중요도를 보여줘서 검색 시스템을 만들거나, 특정 문서에서 키워드의 중요도 키워드 추출을 하는데 쓰이거나 등 되게 많이 사용되고 있다. TF-IDF 자세히 살펴보자면요, TF-IDF는 말그대로 TF랑 IDF랑 곱한 값을 의미한다. 먼저 TF를 보시면, TF란 terim frequency이다. 이는 특정 문서 d개에서 특정 단어 w의 등장 횟수, 즉 각 문서에서 단어의 등장 빈도를 말한다. 그리고 IDF는 DF, document frequency의 역수에 로그를 취한 형태인데, DF는 특정 단어W가 문서 안에서 몇 번..