앞선 선형회귀에선 연속형 수치y값에 대한 예측이 진행되었다면, 로지스틱 회귀의 예측값은 수치가 아닌 범주(Category)이다.
❕ 로지스틱 회귀는 이항분포를 따른다 ❕
이 범주(Category)는 연령, 신장, 몸무게 처럼 연속형 수치로 나타내 수 있는 것이 아니라 성별, 국가, 인종과 같은 범주형 값이고, 이때 로지스틱 회귀는 0또는 1의 값만을 갖게 된다. 여기서 0과 1은 수치적 의미를 갖는다기 보다 오직 범주를 구분하기 위한 0(해당 없음), 1(해당 있음)을 뜻한다. 다시 말해 로지스틱 회귀는 선형 회귀와 다르게 종속 변수(예측하고자 하는 값)가 Bernoulli Distribution = 이항 분포를 따르는 것이다.


❕ 로지스틱 회귀에서 로짓변환 ❕
수치형 변수 또는 범주형 변수를 input했을 때 범주형 y값이 나오는 원리를 잠시 짚고 넘어가보자.
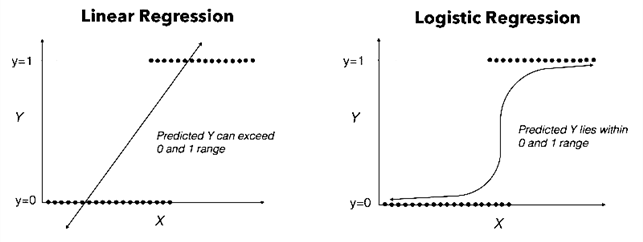
먼저 y가 아래와 같이 0 or 1(사망/생존, 실패/성공, 불합격/합격)이라면 선형회귀로는 fitting하기가 힘들다. 구하는 data의 값을 hypothesis 함수(여기선 linear function)에 넣으면 fitting 되지 못한 연속적인 수치화된 값이 얻어진다. 그래서 우리가 원하는 방향으로 사용하기 위해서 새로운 함수가 필요한데 곡선으로 fitting하기 위해 사용하는 것이 logistic함수 = 로짓변환이다.

로짓 변환을 알기 전에 알아두어야 할 것은 바로 로그오즈비이다.

위의 과정으로 우리가 알고 싶은 label값인 p_i에 대한 식이 완성되고, 저 식이 바로 시그모이드 함수식이다. 함수를 통해 계산되는 0과 1 사이의 값은 정의되는 Decision Boundary를 기준으로 바운더리 이상은 1, 이하는 0 과 같이 분류된다. decision boundary는 하나의 실수가 될 수도 있고, 하나의 수식이 될 수도 있다.
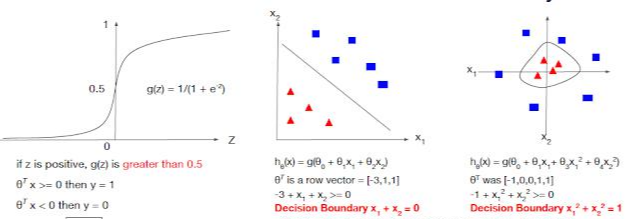
그렇기에 로지스틱 회귀모형은 일종의 분류모델로 사용되곤 한다. 로지스틱 모형은 아래와 같은 sigmoid함수 형태로 나타나는데 여기서 0일 때는 0.5의 확률을 가지고 x값이 커질수록 1로, x값이 작아질수록 0으로 수렴하는 확률을 가지는 함수이다. 이렇게 값이 나올 확률을 0에서 1사이로만 반환해서 최종적으로 binary하게 이진 분류를 하는 것이다. 주로 binary 분류 (Success/Failure) 문제에 사용되지만 multi-class 분류 (Cats, Dogs, Sheep) 또는 ordinal 분류 (Low, Medium, High) 문제에도 사용할 수 있다.
'데이터 스터디 > Stats\ML' 카테고리의 다른 글
| 06. Gradient Descent (0) | 2022.02.27 |
|---|---|
| 05. Loss function(손실함수) - 회귀&분류 (0) | 2022.02.19 |
| 04-1. Regression(회귀) - 선형회귀 (0) | 2022.02.12 |
| [?!] cost function과 loss function 차이 (0) | 2022.02.11 |
| 03 + 머신러닝의 목표 (0) | 2022.02.09 |