Regression : time-series regression 시계열
작성자 : 14기 김유민
Kaggle : Predict Future Sales 커널 필사
- 대회 소개
- 링크 : https://www.kaggle.com/c/competitive-data-science-predict-future-sales
- 비즈니스 소프트웨어 기업 1c company의 일별 판매 내역 데이터가 제공됨
- 다음 달 해당 스토어에서 판매되는 제품량 예측
- 상점 및 제품 목록은 매월 약간씩 변경되며 이러한 상황을 처리할 수 있는 강력한 모델을 만들자.
- 데이터 파일
- sales_train.csv - 2013년 1월부터 2015년 10월까지의 일일 과거 데이터. train set
- test.csv - 상점과 제품의 2015년 11월 판매량 을 예측 test set.
- sample_submission.csv - 제출 파일
- items.csv - 항목/제품에 대한 추가 정보.
- item_categories.csv - 항목/제품 카테고리에 대한 추가 정보.
- shops.csv- 상점에 대한 추가 정보
- 참고 커널
Model stacking, feature engineering and EDA
Explore and run machine learning code with Kaggle Notebooks | Using data from Predict Future Sales
www.kaggle.com
해당 게시글은 캐글 컴피티션의 공유 코드로 올라와있는 <Model stacking, feature engineering and EDA>를 리뷰한 것입니다. 이 코드는 시계열 데이터 속 변수들과 시간단위를 직접 조정하는 방식으로 진행되며 피쳐들을 늘려나가는 연습을 하기 적합한 코드입니다. 또한 모델링의 성능을 높이기 위해 최종적으로 ensemble하는 과정까지 담고 있습니다. 모든 절차를 설명하기 보단, 전반적인 분석 진행에 있어 큰 비중을 차지하는 핵심 코드를 위주로 소개드릴까 합니다.
※ PC 화면에 최적화되어 있습니다.
# 데이터 준비
# 전처리
# 피쳐 엔지니어링
# 모델링
데이터 준비
> 1. Import Libraries & Modules
# 패키지 설치
import datetime
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
!pip install catboost
from catboost import Pool
from catboost import CatBoostRegressor
from xgboost import XGBRegressor
from xgboost import plot_importance
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# settings : 결과로 바로 그림이 나오도록 + 스타일 서식
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
sns.set(style="darkgrid")
pd.set_option('display.float_format', lambda x: '%.2f' % x)test = pd.read_csv('../input/test.csv', dtype={'ID': 'int32', 'shop_id': 'int32',
'item_id': 'int32'})
item_categories = pd.read_csv('../input/item_categories.csv',
dtype={'item_category_name': 'str', 'item_category_id': 'int32'})
items = pd.read_csv('../input/items.csv', dtype={'item_name': 'str', 'item_id': 'int32',
'item_category_id': 'int32'})
shops = pd.read_csv('../input/shops.csv', dtype={'shop_name': 'str', 'shop_id': 'int32'})
sales = pd.read_csv('../input/sales_train.csv', parse_dates=['date'],
dtype={'date': 'str', 'date_block_num': 'int32', 'shop_id': 'int32',
'item_id': 'int32', 'item_price': 'float32', 'item_cnt_day': 'int32'})대회에서 제공하는 5가지 데이터셋을 모두 불러옵니다.
불러오는 과정에서 dtype을 지정해두면 처리 과정이 한 층 더 단순해질 수 있습니다.
> 2. JOIN 조인
train = sales.join(items, on='item_id', rsuffix='_').join(shops, on='shop_id', rsuffix='_').join(item_categories, on='item_category_id', rsuffix='_').drop(['item_id_', 'shop_id_', 'item_category_id_'], axis=1)
train.describe()
sales, items, item_Category, shop 이 4개의 set들을 하나의 데이터프레임안에서 다뤄주기 위해서 조인을 시켜줍니다.
파이썬에선 기본적으로 left_join 을 취하는데, 여기서 왼쪽 dataframe( sale 데이터)의 모든 행은 train에 보관되고, 이 sales 데이터속에 있는 shop_id 그리고 item_id이 나머지 애들한테도 공통적으로 들어있기 때문에 얘네를 기준으로 해서 동일한 인덱스값에 해당하는 행을 오른쪽 열에 붙여주는 식입니다.
| ID | an Id that represents a (Shop, Item) tuple within the test set |
| shop_id | unique identifier of a shop |
| item_id | unique identifier of a product |
| item_category_id | unique identifier of item category |
| date_block_num | 편의를 위한 월 번호. 2013년 1월 :0, 2013년 2월 :1,,,,,,,, 2015년 10월: 33 |
| date | date in format dd/mm/yyyy |
| item_cnt_day | 하루에 판매된 제품 수 [target] -> 한달에 판매된 제품 수 |
| item_price | current price of an item |
| item_name | name of item |
| shop_name | name of shop |
| shop_name | name of item category |
완성된 하나의 train set 속 우리가 눈에 익혀야할 피쳐들을 잠깐 짚고넘어가면,
- item_count_daty -> 한달에 판매된 제품 수
- date_block_num -> 월을 나타내는 번호
이때 item_count_daty는 month로 묶어 target 변수로 쓰이게 됩니다.
전처리
> 1. Data Leakage
test_shop_ids = test['shop_id'].unique()
test_item_ids = test['item_id'].unique()
# test set에만 있는 shop_id
lk_train = train[train['shop_id'].isin(test_shop_ids)]
# test set에만 있는 item_id
lk_train = lk_train[lk_train['item_id'].isin(test_item_ids)]
print('Data set size before leaking:', train.shape[0]) #293만
print('Data set size after leaking:', lk_train.shape[0]) #122만
- data leakage : training 데이터 밖에서 유입된 정보들로 인한 과적합 문제
- test set에 존재하는 shop_id , item_id 만 사용
2. month 기준으로 aggregate
# month 기준으로 aggregate
train_monthly = train_monthly.sort_values('date').groupby(['date_block_num', 'shop_id', 'item_category_id', 'item_id'], as_index=False)
train_monthly = train_monthly.agg({'item_price':['sum', 'mean'], 'item_cnt_day':['sum', 'mean','count']})
# Rename features.
train_monthly.columns = ['date_block_num', 'shop_id', 'item_category_id', 'item_id', 'item_price', 'mean_item_price', 'item_cnt', 'mean_item_cnt', 'transactions']
train_monthly.head()3. Missing Record 추가 생성
# missing record 생성
shop_ids = train_monthly['shop_id'].unique()
item_ids = train_monthly['item_id'].unique()
empty_df = []
for i in range(34):
for shop in shop_ids:
for item in item_ids:
empty_df.append([i, shop, item])
empty_df = pd.DataFrame(empty_df, columns=['date_block_num','shop_id','item_id'])
# 합치기
train_monthly = pd.merge(empty_df, train_monthly, on=['date_block_num','shop_id','item_id'], how='left')
train_monthly.fillna(0, inplace=True)흥미로웠던 점은, missing record를 임의로 추가를 하는 부분이었습니다.
실제 상황을 좀 반영해주기 위해, 빠진 값들이 있을 것이다는 나름의 합리적인 가정을 하고 missing record를 집어 넣어줍니다. 매 달마다 모든 상품, 그리고 가게에 대해서 한 번씩 0으로 empty된 값을 넣어줍니다.
4. 시간 변수 추가 생성 : year, month
# 시간 변수 추가 생성
train_monthly['year'] = train_monthly['date_block_num'].apply(lambda x: ((x//12) + 2013))
train_monthly['month'] = train_monthly['date_block_num'].apply(lambda x: (x % 12))
5. outlier 제거
train_monthly = train_monthly.query('item_cnt >= 0 and item_cnt <= 20 and item_price < 400000')outlier는 scattor plot을 그려 작가가 정한 임의의 threshold를 기준으로 제거합니다.
피쳐 엔지니어링
> 1. Label 변수 생성
- 일별 판매량 -> 월별 판매량으로 바꾸는 과정.
- 이때 shift(-1) 해서 다음 달 판매량을 shift 땡겨와
# LABEL 생성 : month 별 제품수(item_cnt)의 합
train_monthly['item_cnt_month'] = train_monthly.sort_values('date_block_num').groupby(['shop_id', 'item_id'])['item_cnt'].shift(-1) #다음 달 판매량> 2. rolling
# Rolling (window = 3달).
# Min value
f_min = lambda x: x.rolling(window=3, min_periods=1).min()
# Max value
f_max = lambda x: x.rolling(window=3, min_periods=1).max()
# Mean value
f_mean = lambda x: x.rolling(window=3, min_periods=1).mean()
# Standard deviation
f_std = lambda x: x.rolling(window=3, min_periods=1).std()
function_list = [f_min, f_max, f_mean, f_std]
function_name = ['min', 'max', 'mean', 'std']
for i in range(len(function_list)):
train_monthly[('item_cnt_%s' % function_name[i])] = train_monthly.sort_values('date_block_num').groupby(['shop_id', 'item_category_id', 'item_id'])['item_cnt'].apply(function_list[i])
# Fill the empty std features with 0
train_monthly['item_cnt_std'].fillna(0, inplace=True)rolling은 몇개의 데이터를 가지고 연산을 할건지를 정하는 과정입니다.
데이터들을 순차적으로 3달 (window=3)씩 선택해서 mean처럼 이동평균을 내보낼 수도 있고 그 3달치의 min,max,std도 고려할 수 있습니다.
> 3. lag
# lag
lag_list = [1, 2, 3]
for lag in lag_list:
ft_name = ('item_cnt_shifted%s' % lag)
train_monthly[ft_name] = train_monthly.sort_values('date_block_num').groupby(['shop_id', 'item_category_id', 'item_id'])['item_cnt'].shift(lag)
# Fill the empty shifted features with 0
train_monthly[ft_name].fillna(0, inplace=True)lag수를 정해서 시점을 1,2,3달 간격으로 미뤄서 lag변수를 만듭니다.
> 4. trend 반영
train_monthly['item_trend'] = train_monthly['item_cnt']
for lag in lag_list:
ft_name = ('item_cnt_shifted%s' % lag)
train_monthly['item_trend'] -= train_monthly[ft_name]
train_monthly['item_trend'] /= len(lag_list) + 1trend변수를 생성하는 방법은 lag을 시켰을 때 나온 item_count, 판매량을 lag로 나눠서 1을 더해줍니다.
> 5. Train/validation split
- train set : block_num(3~28),
- validation set : block_num(29~32)
- test : block_num (33)
train_set = train_monthly_p.query('date_block_num >= 3 and date_block_num < 28').copy()
validation_set = train_monthly_p.query('date_block_num >= 28 and date_block_num < 33').copy()
test_set = train_monthly_p.query('date_block_num == 33').copy()
#타겟 변수는 제외
train_set.dropna(subset=['item_cnt_month'], inplace=True)
validation_set.dropna(subset=['item_cnt_month'], inplace=True)
train_set.dropna(inplace=True)
validation_set.dropna(inplace=True)
print('Train set records:', train_set.shape[0])
print('Validation set records:', validation_set.shape[0])
print('Test set records:', test_set.shape[0])
print('Train set records: %s (%.f%% of complete data)' % (train_set.shape[0], ((train_set.shape[0]/train_monthly_p.shape[0])*100)))
print('Validation set records: %s (%.f%% of complete data)' % (validation_set.shape[0], ((validation_set.shape[0]/train_monthly_p.shape[0])*100)))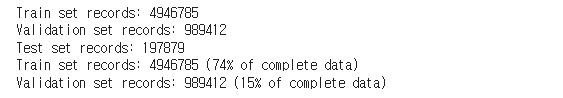
train/validation split 할 때 랜덤하게 나누기 보단 (위에서 lag를 최대 3씩 했으니 date number 0,1,2 은 빼고) 비교적 최근인 걸 validation에 넣고 ,마지막으로 열번호33을 test에 넣습니다. 약 5:1의 비율로 나눠진 것을 확인할 수 있습니다.
> 6. Mean Encoding
# Shop mean encoding.
gp_shop_mean = train_set.groupby(['shop_id']).agg({'item_cnt_month': ['mean']})
gp_shop_mean.columns = ['shop_mean']
gp_shop_mean.reset_index(inplace=True)
# Item mean encoding.
gp_item_mean = train_set.groupby(['item_id']).agg({'item_cnt_month': ['mean']})
gp_item_mean.columns = ['item_mean']
gp_item_mean.reset_index(inplace=True)
# Shop with item mean encoding.
gp_shop_item_mean = train_set.groupby(['shop_id', 'item_id']).agg({'item_cnt_month': ['mean']})
gp_shop_item_mean.columns = ['shop_item_mean']
gp_shop_item_mean.reset_index(inplace=True)
# Year mean encoding.
gp_year_mean = train_set.groupby(['year']).agg({'item_cnt_month': ['mean']})
gp_year_mean.columns = ['year_mean']
gp_year_mean.reset_index(inplace=True)
# Month mean encoding.
gp_month_mean = train_set.groupby(['month']).agg({'item_cnt_month': ['mean']})
gp_month_mean.columns = ['month_mean']
gp_month_mean.reset_index(inplace=True)
# Add meand encoding features to train set.
train_set = pd.merge(train_set, gp_shop_mean, on=['shop_id'], how='left')
train_set = pd.merge(train_set, gp_item_mean, on=['item_id'], how='left')
train_set = pd.merge(train_set, gp_shop_item_mean, on=['shop_id', 'item_id'], how='left')
train_set = pd.merge(train_set, gp_year_mean, on=['year'], how='left')
train_set = pd.merge(train_set, gp_month_mean, on=['month'], how='left')
# Add meand encoding features to validation set.
validation_set = pd.merge(validation_set, gp_shop_mean, on=['shop_id'], how='left')
validation_set = pd.merge(validation_set, gp_item_mean, on=['item_id'], how='left')
validation_set = pd.merge(validation_set, gp_shop_item_mean, on=['shop_id', 'item_id'], how='left')
validation_set = pd.merge(validation_set, gp_year_mean, on=['year'], how='left')
validation_set = pd.merge(validation_set, gp_month_mean, on=['month'], how='left')encoding 으로는 정수이지만 카테고리 범주형인 shop_id, item_id, year, month를 mean encoding 시킵니다. shop id를 기준으로하는 월별 판매량을 넣고 item_id를 기준으로 하는 판매량을 넣는 과정을 반복해 train,validaton에 적용합니다.
모델링
아래부턴 부스팅모델, 트리기반모델, 클러스터링회귀모델에 대한 코드입니다.
모델링 코드는 눈에 다들 많이 익어있을 것이라 생각됩니다.
따라서 fit / transform을 하는 경우 & train / prediciction이 들어가는 순서 & 각 모델별로 피쳐인포턴스 보는 방법 등 자신이 헷갈리는 부분을 명확히 짚고 넘어가도록 합시다.
> 1. catboost
cat_features = [0, 1, 7, 8]
catboost_model = CatBoostRegressor(
iterations=500,
max_ctr_complexity=4,
random_seed=0,
od_type='Iter',
od_wait=25,
verbose=50,
depth=4
)
catboost_model.fit(
X_train, Y_train,
cat_features=[],
eval_set=(X_validation, Y_validation)
)
feature importance
eature_score = pd.DataFrame(list(zip(X_train.dtypes.index, catboost_model.get_feature_importance(Pool(X_train, label=Y_train, cat_features=[])))), columns=['Feature','Score'])
feature_score = feature_score.sort_values(by='Score', ascending=False, inplace=False, kind='quicksort', na_position='last')
plt.rcParams["figure.figsize"] = (19, 6)
ax = feature_score.plot('Feature', 'Score', kind='bar', color='c')
ax.set_title("Catboost Feature Importance Ranking", fontsize = 14)
ax.set_xlabel('')
rects = ax.patches
labels = feature_score['Score'].round(2)
for rect, label in zip(rects, labels):
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()/2, height + 0.35, label, ha='center', va='bottom')
plt.show()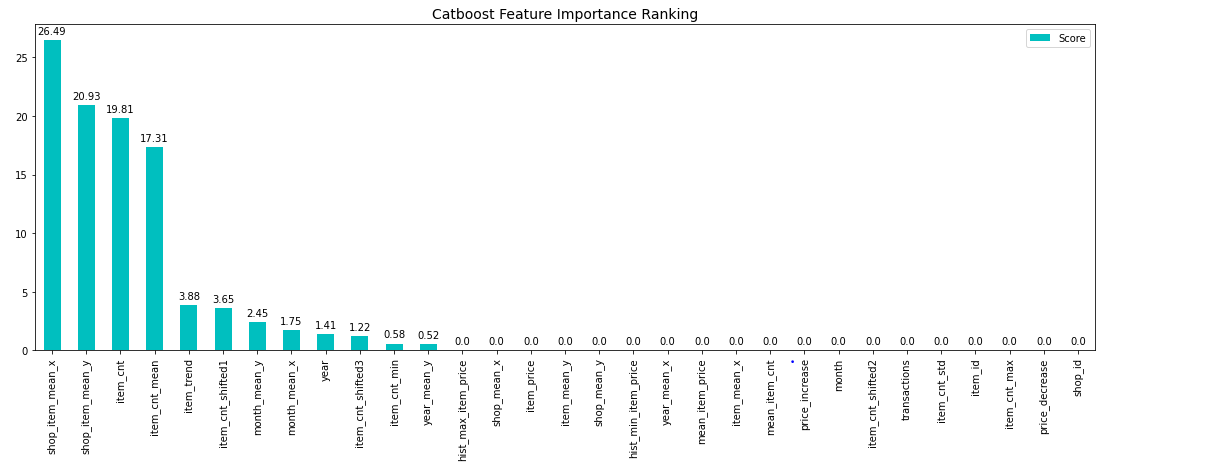
catboost 모델 안에서의 피쳐 중요도를 확인해봅니다.
catboost_train_pred = catboost_model.predict(X_train)
catboost_val_pred = catboost_model.predict(X_validation)
catboost_test_pred = catboost_model.predict(X_test)
print('Train rmse:', np.sqrt(mean_squared_error(Y_train, catboost_train_pred)))
print('Validation rmse:', np.sqrt(mean_squared_error(Y_validation, catboost_val_pred)))
> 2 . XGBoost
xgb_features = ['item_cnt','item_cnt_mean','item_cnt_std', 'item_cnt_shifted1',
'item_cnt_shifted2', 'item_cnt_shifted3', 'shop_mean_x','shop_mean_y',
'shop_item_mean_x','shop_item_mean_y', 'item_trend', 'mean_item_cnt']
xgb_train = X_train[xgb_features]
xgb_val = X_validation[xgb_features]
xgb_test = X_test[xgb_features]xgb_model = XGBRegressor(max_depth=8,
n_estimators=500,
min_child_weight=1000,
colsample_bytree=0.7,
subsample=0.7,
eta=0.3,
seed=0)
xgb_model.fit(xgb_train,
Y_train,
eval_metric="rmse",
eval_set=[(xgb_train, Y_train), (xgb_val, Y_validation)],
verbose=20,feature importance
plt.rcParams["figure.figsize"] = (15, 6)
plot_importance(xgb_model)
plt.show()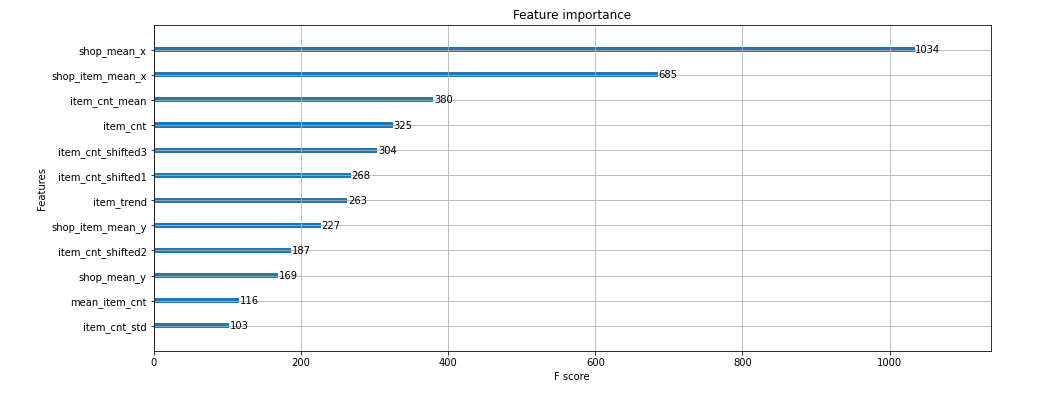
xgb_train_pred = xgb_model.predict(xgb_train)
xgb_val_pred = xgb_model.predict(xgb_val)
xgb_test_pred = xgb_model.predict(xgb_test)
print('Train rmse:', np.sqrt(mean_squared_error(Y_train, xgb_train_pred)))
print('Validation rmse:', np.sqrt(mean_squared_error(Y_validation, xgb_val_pred)))XGBoost모델의 feature importance를 확인해줍니다.

> 3. random forest
rf_features = ['item_cnt','item_cnt_mean','item_cnt_std', 'item_cnt_shifted1',
'item_cnt_shifted2', 'item_cnt_shifted3', 'shop_mean_x','shop_mean_y',
'shop_item_mean_x','shop_item_mean_y', 'item_trend', 'mean_item_cnt']
rf_train = X_train[rf_features]
rf_val = X_validation[rf_features]
rf_test = X_test[rf_features]rf_model = RandomForestRegressor(n_estimators=50, max_depth=7, random_state=0, n_jobs=-1)
rf_model.fit(rf_train, Y_train)rf_train_pred = rf_model.predict(rf_train)
rf_val_pred = rf_model.predict(rf_val)
rf_test_pred = rf_model.predict(rf_test)
print('Train rmse:', np.sqrt(mean_squared_error(Y_train, rf_train_pred)))
print('Validation rmse:', np.sqrt(mean_squared_error(Y_validation, rf_val_pred)))
> 4. linear regression
# Use only part of features on linear Regression.
lr_features = ['item_cnt', 'item_cnt_shifted1', 'item_trend', 'mean_item_cnt', 'shop_mean_x', 'shop_mean_y']
lr_train = X_train[lr_features]
lr_val = X_validation[lr_features]
lr_test = X_test[lr_features]정규화 : minmax_scaler
# 정규화
lr_scaler = MinMaxScaler()
lr_scaler.fit(lr_train)
lr_train = lr_scaler.transform(lr_train)
lr_val = lr_scaler.transform(lr_val)
lr_test = lr_scaler.transform(lr_test)★주의★
정규화 스케일링을 할 때,
train set은 fit.transform() 을 시켜주되, test set에 대해서는 transform()만 해주어야합니다.
이는 train set에 대해서 fit한 scaler 객체를 이용해서 test data에 그대로 사용해야하기 때문입니다.
test에 다른 scaler를 fit하지 않도록, 그대로 transform를 해주어야합니다.
lr_model = LinearRegression(n_jobs=-1)
lr_model.fit(lr_train, Y_train)
lr_train_pred = lr_model.predict(lr_train)
lr_val_pred = lr_model.predict(lr_val)
lr_test_pred = lr_model.predict(lr_test)
print('Train rmse:', np.sqrt(mean_squared_error(Y_train, lr_train_pred)))
print('Validation rmse:', np.sqrt(mean_squared_error(Y_validation, lr_val_pred)))
> 5. KNN regressor
# Use only part of features on KNN.
knn_features = ['item_cnt','item_cnt_mean','item_cnt_std', 'item_cnt_shifted1',
'item_cnt_shifted2', 'item_cnt_shifted3', 'shop_mean_x','shop_mean_y',
'shop_item_mean_x','shop_item_mean_y', 'item_trend', 'mean_item_cnt']# Subsample train set (using the whole data was taking too long).
X_train_sampled = X_train[:100000]
Y_train_sampled = Y_train[:100000]
knn_train = X_train_sampled[knn_features]
knn_val = X_validation[knn_features]
knn_test = X_test[knn_features]정규화 : minmax_scaler
# 정규화
knn_scaler = MinMaxScaler()
knn_scaler.fit(knn_train)
knn_train = knn_scaler.transform(knn_train)
knn_val = knn_scaler.transform(knn_val)
knn_test = knn_scaler.transform(knn_test)knn_model = KNeighborsRegressor(n_neighbors=9, leaf_size=13, n_jobs=-1)
knn_model.fit(knn_train, Y_train_sampled)
knn_train_pred = knn_model.predict(knn_train)
knn_val_pred = knn_model.predict(knn_val)
knn_test_pred = knn_model.predict(knn_test)
# 평가
print('Train rmse:', np.sqrt(mean_squared_error(Y_train_sampled, knn_train_pred)))
print('Validation rmse:', np.sqrt(mean_squared_error(Y_validation, knn_val_pred)))
> ensemble model<
이 사용해준 모델들(부스팅, tree기반, 클러스터링모델)을 가지고 앙상블 모델까지 만들어줍니다.
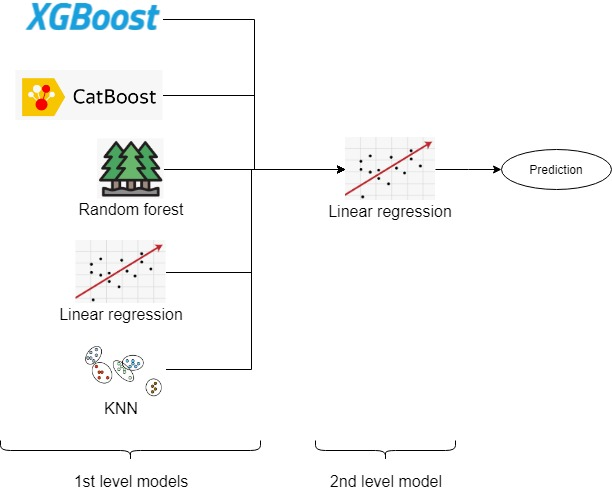
Ensemble 구조 :
- 1st level:
- Catboost
- XGBM
- Random forest
- Linear Regression
- KNN
- 2nd level;
- Linear Regression
# train set
first_level = pd.DataFrame(catboost_val_pred, columns=['catboost'])
first_level['xgbm'] = xgb_val_pred
first_level['random_forest'] = rf_val_pred
first_level['linear_regression'] = lr_val_pred
first_level['knn'] = knn_val_pred
first_level['label'] = Y_validation.values
first_level.head(20)# test set
first_level_test = pd.DataFrame(catboost_test_pred, columns=['catboost'])
first_level_test['xgbm'] = xgb_test_pred
first_level_test['random_forest'] = rf_test_pred
first_level_test['linear_regression'] = lr_test_pred
first_level_test['knn'] = knn_test_pred
first_level_test.head()
meta_model = LinearRegression(n_jobs=-1)
first_level.drop('label', axis=1, inplace=True)
meta_model.fit(first_level, Y_validation)ensemble_pred = meta_model.predict(first_level)
final_predictions = meta_model.predict(first_level_test)
print('Train rmse:', np.sqrt(mean_squared_error(ensemble_pred, Y_validation)))
simple linear regression 을 통해 1st level model predictions을 결합해준 모델을 모두 앙상블 모델에 사용해줍니다. prediction값을 이용해 최종 RMSE값을 산출해내면 완성입니다 :)
'데이터 스터디 > Stats\ML' 카테고리의 다른 글
| 08-1. 정규화 : L2 정규화, Ridge regression (0) | 2022.03.05 |
|---|---|
| 07. 과적합(Overfitting)과 정규화(Regularization) (0) | 2022.03.04 |
| [?!] learning rate (0) | 2022.02.28 |
| 06. Gradient Descent (0) | 2022.02.27 |
| 05. Loss function(손실함수) - 회귀&분류 (0) | 2022.02.19 |