3장. DATA STEP 1
DATA Step에는 일반적으로 다음 중 하나의 문장이 있다.
INPUT, SET, MERGE, UPDATE
(이중에 input, set, merge 는 배운 상태, update는 초면 .. )
# 데이터 입력 방법
-list input(자유 입력), - column input(열 지정 입력) - formatted Input(포맷 입력)
1. 자유 입력_List Input
- INPUT 문과 CARDS문 사용 (앞에서 흔히 쓰던 거)
- INPUT : $는 문자형 변수에 사용
- CARDS : INPUT 자료의 개수만큼 관측값 입력, 빈칸(스페이스바)로 구분하기
- RUN : 단계가 끝남
* 자유 입력 시 주의할 점 !
input에 지정한 변수 개수랑 card에 넣은 관측값 행,열의 수에 따라 결과값 다르게 나옴.
EX1) 이건 x.y.z에 2열씩 들어가 => 젤 정상적

EX3) 이건 불안정한 dataset이긴 한데, 일단 x가 1, y가 2읽고, z는 다음 줄 3 읽어. 같은 줄 4.5는 소실
그리고 그 다음 줄 6 7 8이 읽힘
EX4) 순서대로 1 2 3 읽고 같은 줄 4는 소실/ x가 5, y가 6, z가 다음 줄 7 읽고 같은 줄 8 소실/
다음 줄 9 0 1은 그대로 읽힘
음 이걸 해결하기 위해서는 '/' , '#n' , '@n' 을 사용해주면 된다.
/ : 포인터의 위치를 다음 줄의 첫 열로
#n : 줄포인터. 포인터의 위치를 n번째 줄의 첫 열로
@n : 열 포인터. n번째 열로 자료의 입력 시점을 이동
1. 일단 마구잡이로 넣어봄
2. y 다음에 #2를 넣어주면 포인터의 위치를 y 다음인 z는 2번째 줄의 첫 열이 시작함
3. y다음에 / 를 넣어주면 포인트의 위치는 바로 다음 줄의 열의 첫 열로 시작함
4. #2번 #3번을 응용해서 y다음에 /넣으면 z는 두번째 줄 첫 열 3.
z 다음에 #3이면 w는 세번째 줄 첫 열부터 시작
@n은 이런 단순한 1자리 숫자 예시로는 잘 파악이 안되서 ㅠㅠㅠ 뒤에 나올 예시들에서 보겠음
또 다른 방법으로 데이터를 읽을 때 @@를 사용할 수도 있다,
-@@을 이용하면 쓰여진 줄들을 다 읽어낸다.
이렇게 앞에 2열만 읽어내던 걸
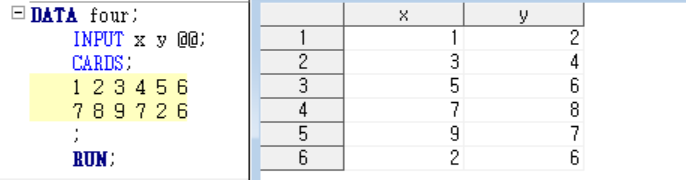
x, y에 다 읽어버린당
2. 열 지정 입력_Column Input
- INPUT 문과 CARDS문 사용
- 칼럼 인풋은 ! 자료가 빈칸으로 구분되어 있지 않거나 / 몇 개의 자료를 건너 띄고 필요한 자료만 읽을 때 사용
- 직접 읽을 열을 지정해줘서 필요한 것만 골라서 쓸 수 있음
EX1) 일단 one_1 이라는 데이터셋을 자유입력으로 넣어봄
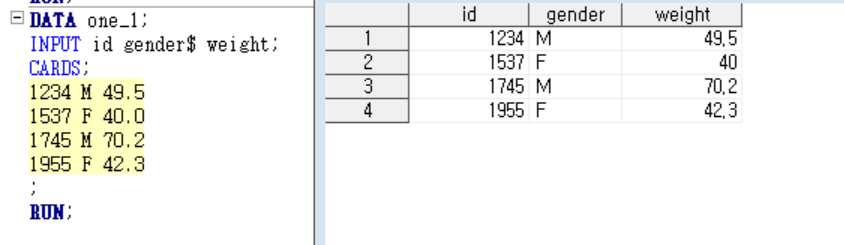
EX2) 그리고 칼럼 인풋 방법으로 열 번호를 지정해서 넣어봄

결과는 자유입력이랑 똑같은 걸 볼 수 있음
이게 id 4글자가 4칸에 들어가고 gender 한 글자가 5-6칸 중 6칸에 들어가고 weight
가 7-12칸 중에서 그 중간에 들어감.


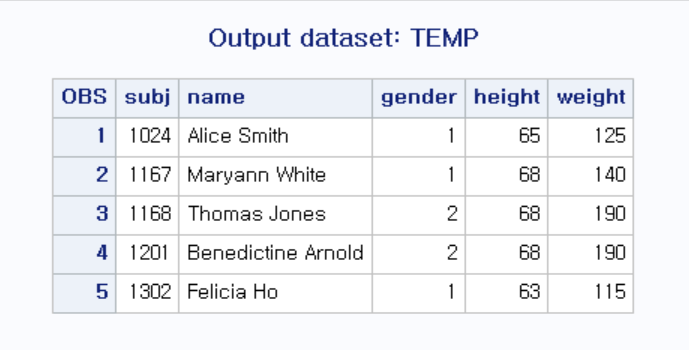
이쯤 되면 의문점이 든다... 내가 그랬거든... 물음표 가득
자유 인풋이랑 결과가 똑같은데 이거 왜씀 ..?
=>보니까 스페이스바 없이 따닥 따닥 붙여쓸 경우에 칼럼을 지정해줘서 결과가 이쁘게 나오게 하려는 용도다 !

이렇게 CARDS부분에 띄워쓰기가 없을 때 칼럼을 지정해주는 것 !
따라서 순서는 CARDS 부분에 어떻게 쓰여졌는지 보고 INPUT 부분에서 자의적으로 칼럼 지정해주면 됨
3. 포맷 입력_Formatted Input
- format은 전체 자릿수. 소수점 밑자리 수 형태
- 자료에서 소수점이 주어지면 fomat에서의 소수점 밑자리 수는 무의미해진다.
-a. = a.0
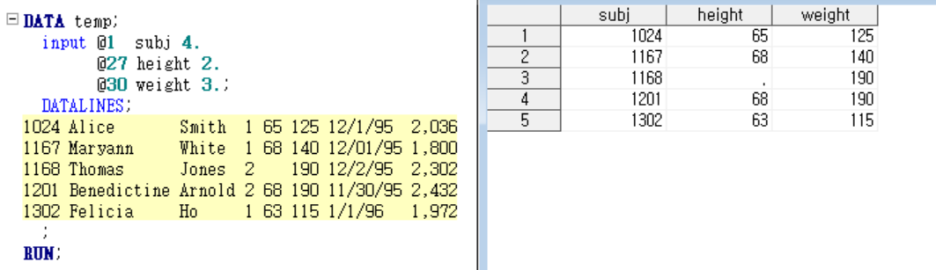
여기서 @1은 subj을 읽기 위해 1열을, @27은 height를 읽기 위해 27번째 열을, @30은 weight를 읽기 위해 30열을 보라는 뜻
4. 은 4자리 수라는 것을 의미함. 4.0이라고 할 수도 있슴. 4 (without the period) 은 안됨
4. 은 informat(입력형식)이 w.(w 자릿수의 정수로 표현) 인 것.
이때 만약에 4.0 이 아니라 4.1 이라고 하면 소수 첫째자리를 가진다는 의미!! 그래서 밑에 처럼 나옴
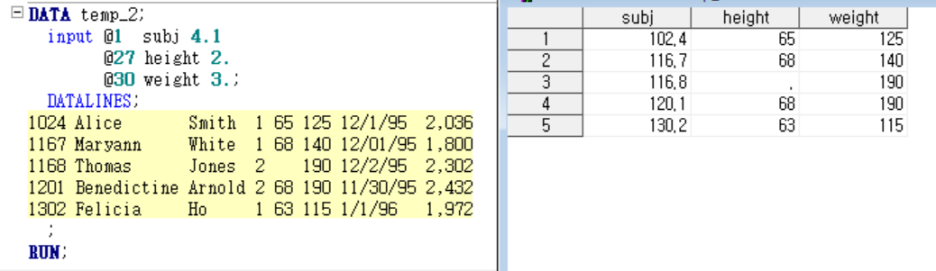
EX2) 수업 예시

이때 CARDS 자료 넣는 부분에 소수점이 이미 있으면 4.1을 하든 4.2를 하든 다 똑같음
그리고 gender 에 2. 넣어도 ok 3. 넣어도 ok 근데 1. 넣으면 안뜨고 4. 넣으면 뒤에 숫자랑 같이 나오게 됨 ㅠ
하...근데 이거 하다가 갑자기 정상적으로 돌렸는데 자꾸 안나와서 애먹었다 ㅠㅠㅠㅠ 대체 왜지....
자료 넣어도 안나오면 다 삭제하고 기본적인 INPUT x y 하나 만들어서 정상적으로 돌아가게 하고 다시 해보자 ..!
EX3) 수업 예시 2
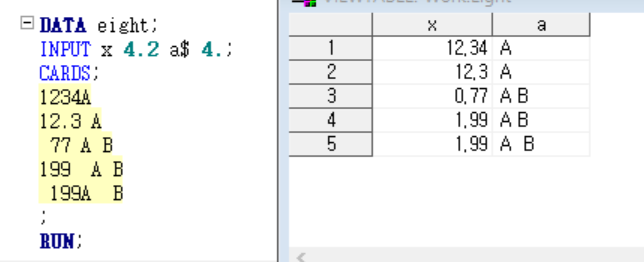
x 4.2니까 x 숫자부분에는 항상 소수점 2자리 수가 나오고, 혹 CARDS 값 안에 소수점 있으면 무의미한 것
하 ㅠㅠ 이제 이해된다..ㅠ
# 데이터 읽기 방법
-set -infile
위에는 데이터 입력 방법이었다면, 이제 데이터 읽기 방법 !
1. set 읽기
- set은 기존 data set을 읽을 때 사용하는 문장
- 기본으로 입력 sas data set의 모든 변수와 모든 관측치를 읽어 옴

=> kusas 라이브러리에 있는 boston 데이터 셋을 SET문으로 불러와서
work 라이브러리의 subset1이라는 이름으로 저장
[수업 예시]

class 라는 데이터셋을 새로 만든 다음, new데이터 셋으로 다시 저장한다.
이때 score 변수가 추가되서 변수는 7개

위에 있던 new 데이터셋에서 new1을 다시 만든다.
이때 average 변수가 추가되서 변수는 8개!
2. INFILE 문
-외부 파일에서 데이터 가져오기.
- CARDS 문을 사용하지 않고 직접 불러오기.
* 파일 참조명 형 / *완전경로파일명


이렇게 infile만 해놓으면 table이 안만들어진다.
다음 과정을 다 완수해야만 view table 가능함
[수업 예시]

'데이터 스터디 > SAS' 카테고리의 다른 글
| SAS - 변수 속성 할당 (0) | 2023.03.22 |
|---|---|
| SAS - 함수(문자, 난수, 날짜, 숫자 절단, 형변환) (2) | 2023.03.22 |
| SAS - 데이터 읽기 실습 (input, infile, proc import, dlm='') (0) | 2023.03.22 |
| SAS - raw 데이터 읽기 (length, & : 연산자) (0) | 2023.03.22 |
| SAS - 라이브러리 설정, DATA STEP, PROC STEP (0) | 2023.03.22 |