3장. DATA STEP 1
이번엔 저번에 다루었던 RAW DATA 읽기 명령문을 사용해서, 데이터 실습해보자
이때 잠깐, WORK 탐색기에 너무 많은 데이터셋이 저장되어 있다.
이를 지울려면 하나 하나 지울수도 있지만 PROC DELETE DATA=삭제하려는 데이터셋; RUN; 을 해보자
EX. proc DELETE data=one1-one7; run;
1. COLUMN INPUT : 고정 포맷 & 표준 데이터 유형
- 열 번호 지정
- 자료값이 고정된 열을 갖고 있어야 함 : 시작 위치 - 끝 위치 표시
-- 문법 : 변수명 / 변수유형($인지 아닌지) / 시작위치-끝위치
EX. age 1-2, gen$ 6-18, gen$3-3 = gen$3

COLOUMN INPUT은 시작위치, 끝 위치를 지정하기 때문에
각 변수들이 다 그 위치에 속하게끔 직접 띄워써서 자리를 맞춘다.
* 저렇게 이름에 띄워쓰기가 있는 경우에는
INPUT 전에 LENGTH 써서 글자 수 제한두는 걸론 안됨.
LENGTH문은 최대 허용 글자 수를 지정해주는거라
LENGTH name $ 10 하면 10글자 까지 쓸 수 있다라는 의미고
INPUT name $ 10 하면 꼭 10바이트까지가 name에 해당한다는 의미 !
2. FORMATTED INPUT : 고정 포맷 &비 표준 데이터 유형
- 각 레코드의 변수별 데이터 값 시작위치가 동일
- INPUT @입력시작위치 변수명 입력포맷(정수부분.소수점부분)
- INFILE'위치' => CARDS 사용하지 않는다는 뜻
- 순서 : DATA지정 -> INFILE txt읽어오기 -> INPUT 으로 변수 읽기 -> RUN
@열 포인트를 지정해주고
정수부분. 소수부분 지정해준다.
3. LIST INPUT : 자유 포맷 &표준 데이터 유형
-입력 방법은 변수명 변수 유형 ex) age gen $
- 문자열은 공백을 포함하지 않고 8자 이하까지 나옴
- 8자를 초과하는 문자데이터에는 LENGTH 문장으로 미리 선언 ex) LENTH name $ 10 ;
이건 name을 문자형으로 $ 지정해서 최대 8글자밖에 못읽어냄
근데 이제 그 전에 length 문으로 글자 수를 지정해주면
밑에 name $ 해도 글자 수 제한 없어짐
# LENGTH 문
- 변수의 속성을 선언하는 구문
-변수값을 저장하기 위해 사용되는 저장공간, 단위로는 바이트
- INPUT 명령문 앞에 LENGTH 변수명 $ 바이트 ;
-영문자 : 1바이트, 한글 : 2바이트 차지
3.1 LIST INPUT의 구분자 읽기
- 일단 직접 텍스트 파일에 들어가서 구분자가 뭔지 확인해보기
- INFILE 문장안에 dlm='구분자' 로 정의함
** 이때 INFILE 이랑 dlm 안에 내용은 작은 따옴표로 묶어야함
- 구분자 지정을 따로 안하면 공백이 구분자로 인식됨
[수업 예시 1]

+1단계. 일단 넣기
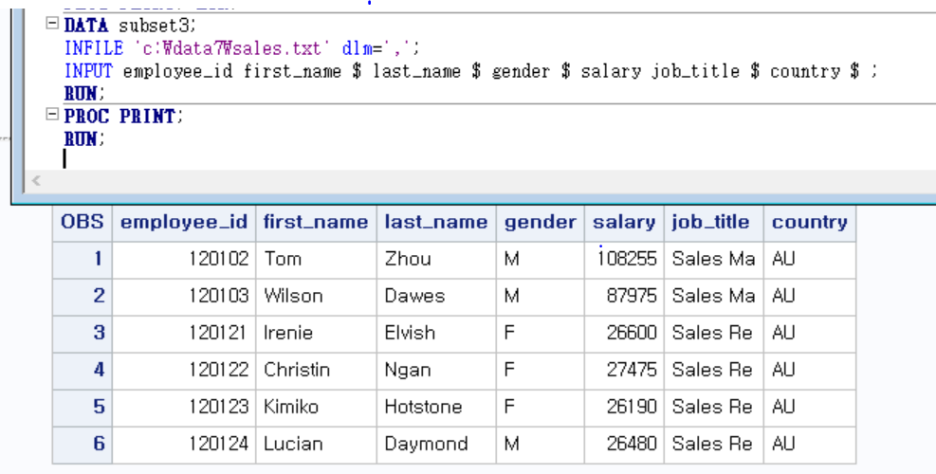
infile 문에서 dlm 으로 구분자 구분 해줌
근데 first_name last_name job_title 이 8글자에서 끊김
+2단계. length문으로 글자수 지정해주기

그러면 first_name에 대해서는 글자가 10글자 꽉 채워서 나옴
근데 length했더니 first_name변수가 맨 앞으로 가버림 !!
+3단계. 변수 순서 정해주기
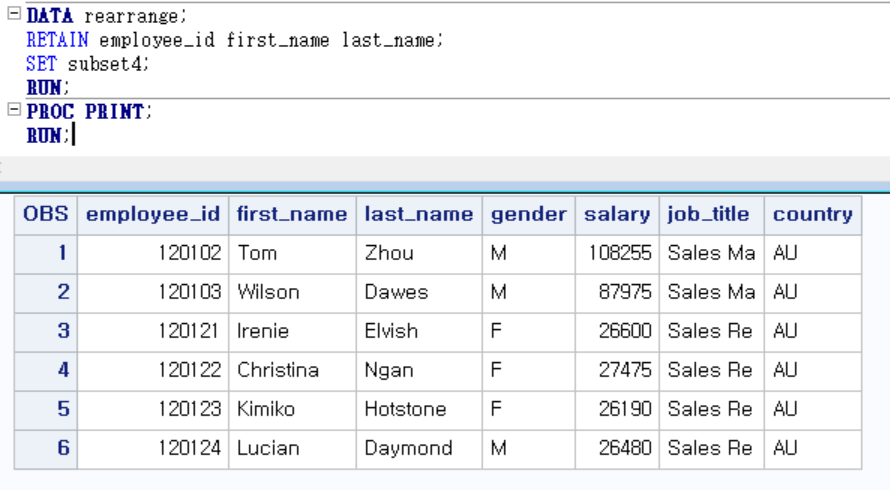
여기서 retain 문으로 순서를 정하고
set문으로 위에서 만들어준 subset4 데이터셋을 복사함
[수업 예시 2]
마지막 변수들 birth_date랑 hire_date 표시하기
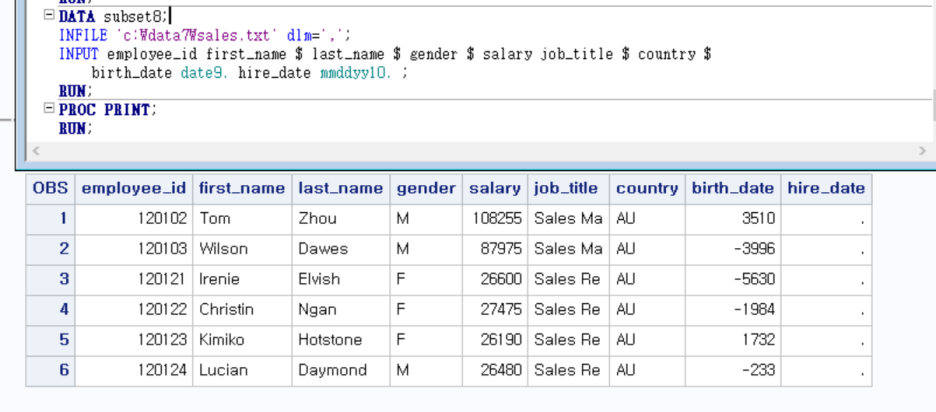
이러면 hire_date 부분에 오류가 뜬다.
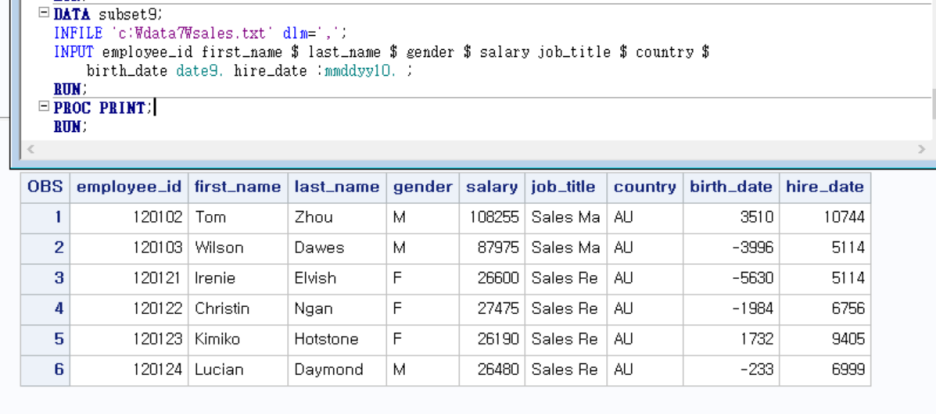
이때 hire_date 뒤에 : 를 붙여주면 해결된다.

birth_date 의 데이터값이 11AUG1969 => 입력 포맷은 : date. = => 저장은 3510으로
hire_date의 데이터값이 06/01/1989 => 입력포맷은 : mmddyy. ==> 저장은 10744로

이때 대체 가능한 방법
1. birth_date :date. hire_date :mmddyy. ;
2. birth_date date9. hire_date :mmddyy. ;
3. birth_date :date. hire_date :mmddyy10.
[수업 예시3]
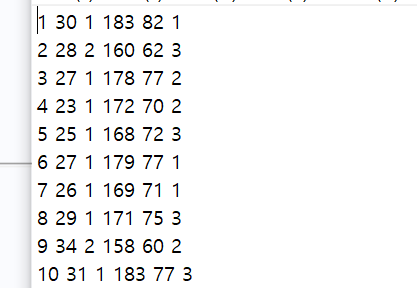
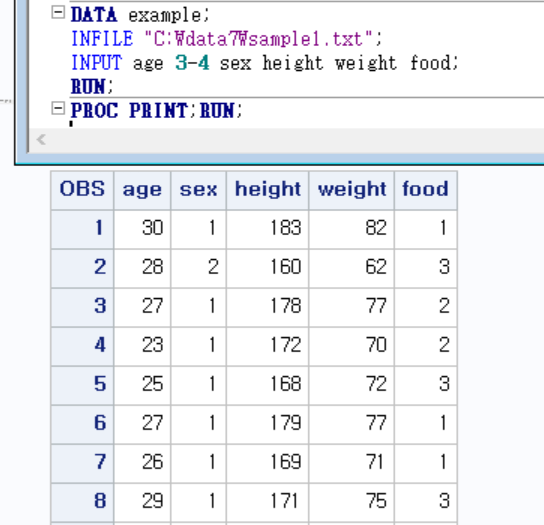
여기에 첫번 째 열은 제외하고 읽어야함
이때 그래서 column input 써서 age 3-4해주면 됨
4. PROC STEP 에서 구분자 구분 (자주 사용은 x)
-PROC import datafile = " "
out = ## dbms = dlm replace;
delimiter='&';
getnames= yes;
run;
[예시 1 - txt파일 불러오기]
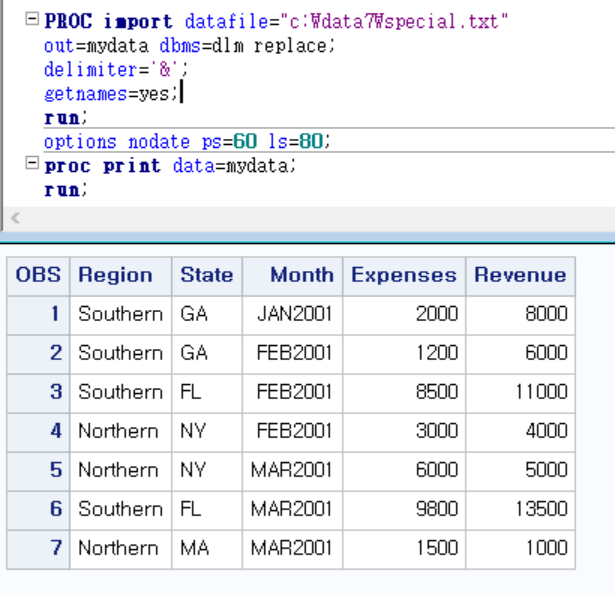
out = mydata : mydata라는 데이터셋에 저장
getnames = yes : 첫열에 있는 변수명을 포함하자
[예시2 - csv 파일 불러오기]
FILENAME REFFILE 'C:\data7\sample.csv'; /*불러올 파일*/
PROC IMPORT DATAFILE=REFFILE
DBMS=CSV /*불러오는 파일 형식*/
OUT=sample_import; /*저장할 형태_폴더명.파일명*/
GETNAMES=YES;
RUN;여기서 불러오는 파일이 xlsx 형식이라면, DBMS=CSV를 DBMS=XLSX로 바꾸면 된다.
===여기까지 data step 1 끝 !=====
'데이터 스터디 > SAS' 카테고리의 다른 글
| SAS - 변수 속성 할당 (0) | 2023.03.22 |
|---|---|
| SAS - 함수(문자, 난수, 날짜, 숫자 절단, 형변환) (2) | 2023.03.22 |
| SAS - raw 데이터 읽기 (length, & : 연산자) (0) | 2023.03.22 |
| SAS - 데이터 입력 및 읽기 (list input, column input, formatted input, set, infile) (1) | 2023.03.22 |
| SAS - 라이브러리 설정, DATA STEP, PROC STEP (0) | 2023.03.22 |