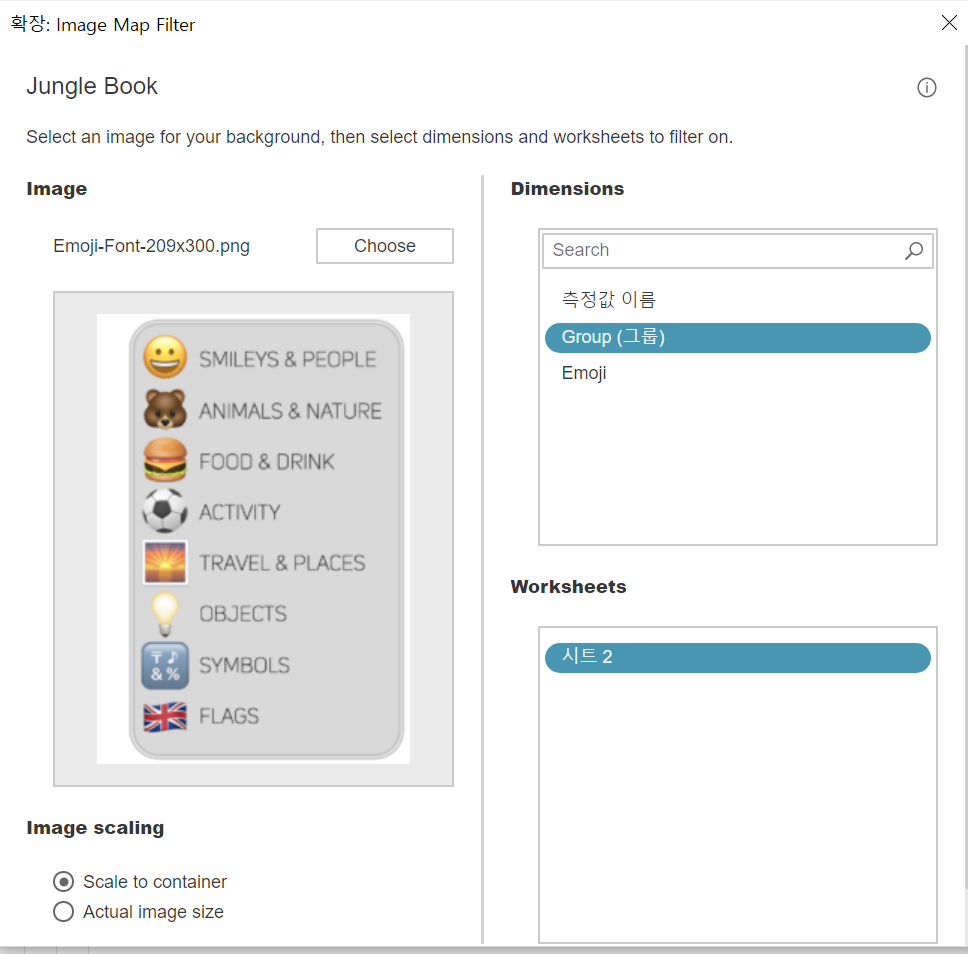
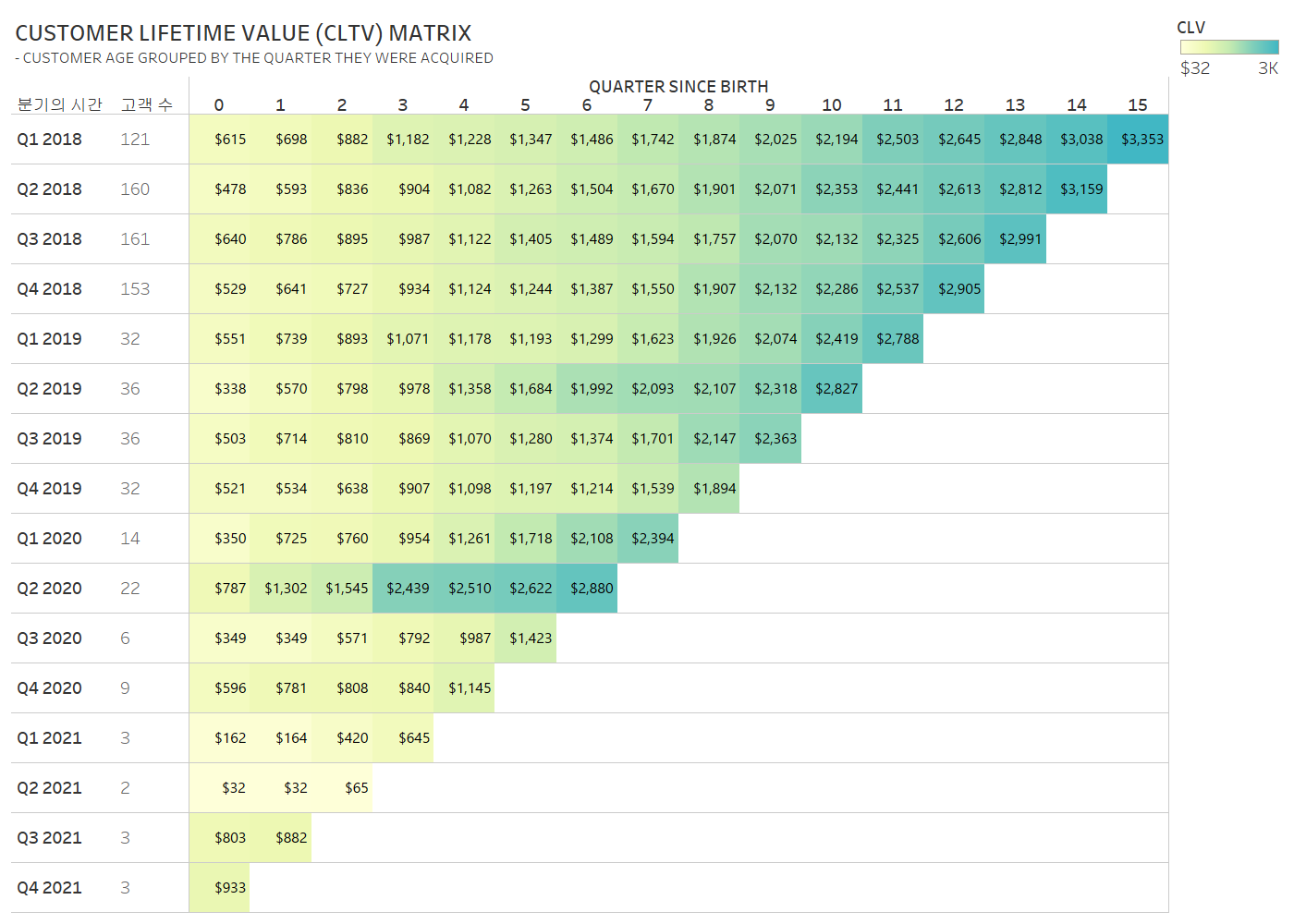
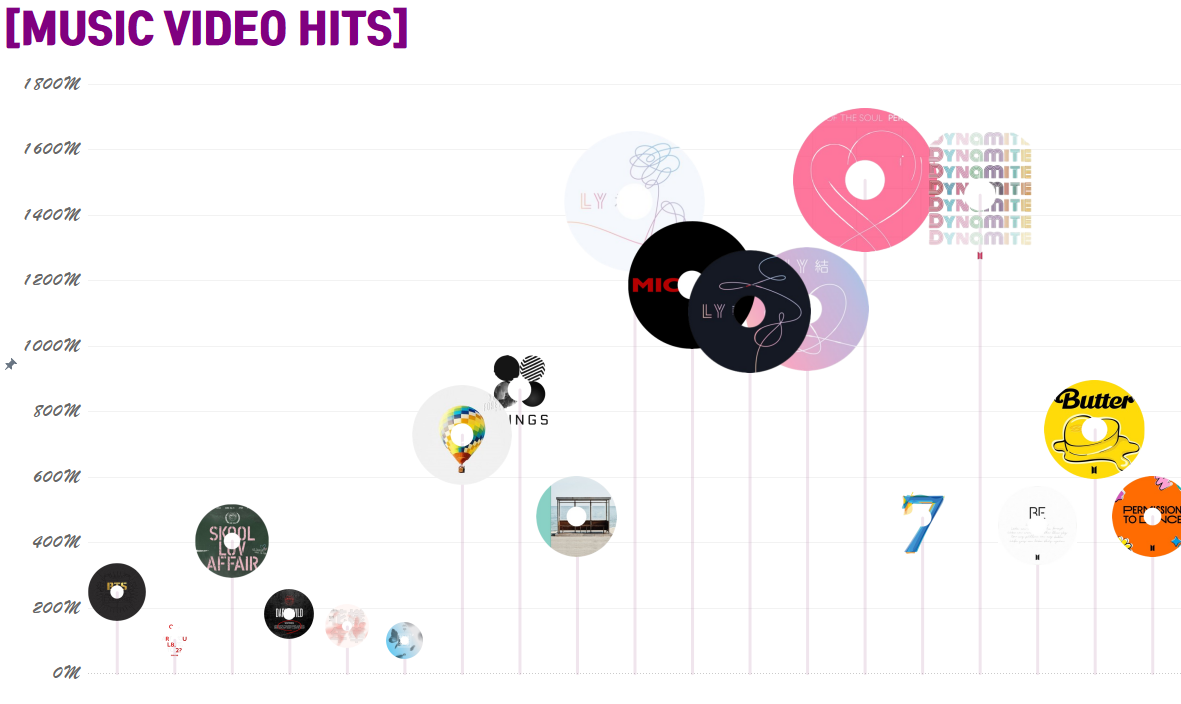
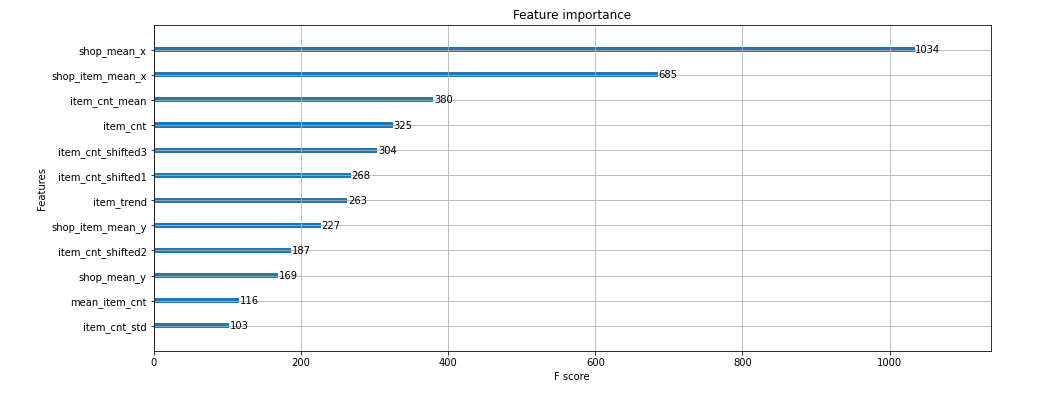
2020 WOW Challenge - Week 7 : Can you use Dashboard Extensions? https://workout-wednesday.com/2021w07tab/ 2020 Week 7 | Tableau : Can you use Dashboard Extensions? – Workout Wednesday When you publish your solution on Tableau Public make sure to take the time and include a link to the original inspiration. Also include the hashtag #WOW2021 in your description to make it searchable! workout-wedne..